|
|
Logistic regression is a powerful statistical method used for modeling binary outcomes. When applying logistic regression in practice, one common challenge is deciding the threshold probability that determines the classification of observations into binary classes (e.g., yes/no, 1/0). This article explores various approaches and considerations for determining an appropriate threshold for a generalized linear model (GLM) in R. Importance of Threshold SelectionAfter fitting a logistic regression model, predictions are based on the predicted probabilities. These probabilities can then be converted into class predictions (e.g., 0 or 1) using a threshold. The choice of threshold directly impacts the model’s classification performance, including metrics such as accuracy, sensitivity, specificity, and the ROC curve. Methods for Deciding ThresholdHere we discuss the main Methods for Deciding Thresholds in the R Programming Language.
Step 1: Load Required Libraries and DatasetWe’ll use the pROC package for ROC curve analysis and the caret package for data preprocessing. For this example, let’s consider the famous Pima Indians Diabetes Database from the caret package, which contains information about diabetic and non-diabetic patients. Output: pregnant glucose pressure triceps insulin mass pedigree age diabetes
1 6 148 72 35 0 33.6 0.627 50 pos
2 1 85 66 29 0 26.6 0.351 31 neg
3 8 183 64 0 0 23.3 0.672 32 pos
4 1 89 66 23 94 28.1 0.167 21 neg
5 0 137 40 35 168 43.1 2.288 33 pos
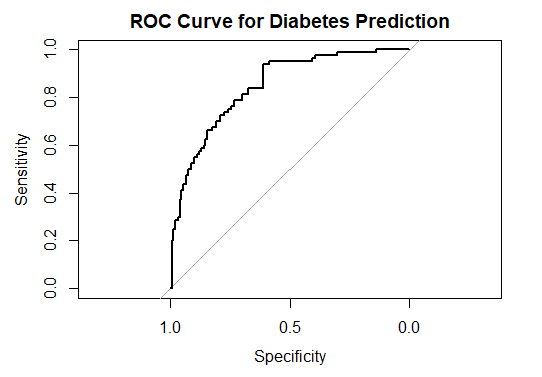
6 5 116 74 0 0 25.6 0.201 30 negStep 2: Preprocess and Split DataNow we will Preprocess and Split Data into training and testing. Step 3: Fit Logistic Regression ModelNow we will fit Logistic Regression Model. Step 4: ROC Curve AnalysisNow we will perform ROC Curve Analysis. Output: Deciding threshold for glm logistic regression model in R Step 5: Determine Optimal ThresholdAt last we will Determine Optimal Threshold. Output: Optimal threshold based on ROC curve: 0.292829
Accuracy: 0.7521739 ConclusionIn this example, we successfully demonstrated how to decide the threshold for a logistic regression model using the Pima Indians Diabetes dataset. By fitting a logistic regression model, predicting probabilities on test data, and analyzing the ROC curve, we identified an optimal threshold that maximizes both sensitivity and specificity. This approach ensures that our model’s predictions align well with the actual outcomes, enhancing its utility in practical applications. Adjusting the threshold based on specific requirements and domain knowledge allows for tailored decision-making and improved predictive performance. |
Reffered: https://www.geeksforgeeks.org
| AI ML DS |
Type: | Geek |
Category: | Coding |
Sub Category: | Tutorial |
Uploaded by: | Admin |
Views: | 22 |