|
|
A decision tree classifier is a well-liked and adaptable machine learning approach for classification applications. It creates a model in the shape of a tree structure, with each internal node standing in for a “decision” based on a feature, each branch for the decision’s result, and each leaf node for a regression value or class label. Decision trees are the fundamental components of random forests. In this article, we will delve into the world of Decision Tree Classifiers using Scikit-Learn, a popular Python library for machine learning. We will explore the theoretical foundations, implementation, and practical applications of Decision Tree Classifiers, providing a comprehensive guide for both beginners and experienced practitioners. Table of Content What is a Decision Tree Classifier?A Decision Tree Classifier is a type of supervised learning algorithm that uses a tree-like model to classify data into different categories. The algorithm works by recursively partitioning the data into smaller subsets based on the values of the input features. Each internal node in the tree represents a feature or attribute, and each leaf node represents a class label. The classification process involves traversing the tree from the root node to a leaf node, with each node providing a decision based on the input features. How Does a Decision Tree Classifier Work?The Decision Tree Classifier algorithm can be broken down into three main steps:
Implementing Decision Tree Classifiers with Scikit-LearnThe DecisionTreeClassifier from Sklearn has the ability to perform multi-class classification on a dataset. The syntax for DecisionTreeClassifier is as follows:
Let’s go through the parameters:
Steps to train a DecisionTreeClassifier Using SklearnLet’s look at how to train a DecisionTreeClassifier using Sklearn on Iris dataset. The phase by phase execution as follows: Step 1: Import Libraries To start, import the libraries you’ll need, such as Scikit-Learn (sklearn) for machine learning tasks. from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_scoreStep 2: Data Loading In order to perform classification jobs, load a dataset. For demonstration, one can utilize sample datasets from Scikit-Learn, such as Iris or Breast Cancer. iris = load_iris()
X = iris.data
y = iris.targetStep 3: Splitting Data Use the train_test_split method from sklearn.model_selection to split the dataset into training and testing sets. X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=99)Step 4: Starting the Model Using DecisionTreeClassifier from sklearn.tree, create an object for the Decision Tree Classifier. clf = DecisionTreeClassifier(random_state=1)Step 5: Training the Model Apply the fit method to match the classifier to the training set of data. clf.fit(X_train, y_train)Step 6: Making Predictions Apply the predict method to the test data and use the trained model to create predictions. y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')Let’s implement the complete code based on above steps. The code is as follows: Output: Accuracy: 0.9555555555555556Hyperparameter Tuning with Decision Tree ClassifierThe performance of a decision tree classifier can be greatly impacted by hyperparameters. Tuning hyperparameters can result in increased performance, reduced overfitting, enhanced generalization, etc. Some of the major hyperparameters in a decision tree classifier are criterion, splitter, max_features, max_depth, min_sample_leaf, max_leaf_nodes, etc. The three most widely used methods for hyperparameter tuning are Grid Search, Random Search and Bayesian optimization. These methods check the different combinations of hyperparameter values that help to find the most effective configuration and fine-tune the decision tree model.
Hyperparmater tuning using GridSearchCVLet’s make use of Scikit-Learn’s GridSearchCV to find the best combination of of hyperparameter values. The code is as follows: Output: Fitting 5 folds for each of 1620 candidates, totalling 8100 fits
best accuracy 0.9714285714285715
DecisionTreeClassifier(criterion='entropy', max_depth=4,
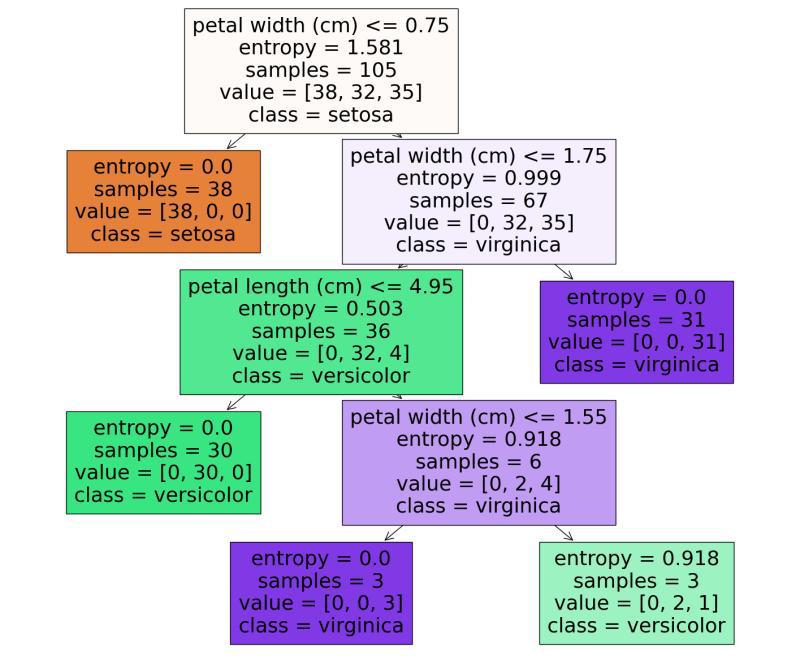
min_samples_leaf=3, random_state=1)Here we defined the parameter grid with a set of hyperparameters and a list of possible values. The GridSearchCV evaluates the different hyperparameter combinations for the DecissionTree Classifier and selects the best combination of hyperparameters based on the performance across all k folds. Visualizing the Decision Tree ClassifierDecision Tree visualization facilitates interpretation and comprehension of the model’s choices. We’ll plot feature importances obtained from the Decision Tree model to see which features have the greatest predictive power. Here we fetch the best estimator obtained from the gridsearchcv as the decision tree classifier. Output: DecisionTree Visualization Let’s look at how trees make predictions based on the above diagram. We can start from the root node (depth 0, at the top). The root node checks whether the flower petal width is less than or equal to 0.75. If it is, then we move to the root’s left child node (depth1, left). Here, the left node doesn’t have any child nodes, so the classifier will predict the class for that node (setosa). If the petal width is greater than 0.75, then we must move down to the root’s right child node (depth 1, right). Here the right node is not a leaf node, so node check for the condition until it reaches the leaf node. Decision Tree Classifier With Spam Email Detection DatasetSpam email detection dataset is trained on decision trees to predict e-mails as spam or ham (safe). As scikit-learn is also known as Sklearn it is used as sklearn library for this implementation Let’s load the spam email dataset and plot the count of spam and ham emails using matplotlib. The code is as follows: Output  Spam and Ham Email Count As a next step, let’s prepare the data for decision tree classifier. The code is as follows: As part of data preparation, the category string is replaced with a numeric attribute, RegexpTokenizer is used for message cleaning, and CountVectorizer() is used to convert text documents to a matrix of tokens. Finally, the dataset is separated into training and test sets. Now we can use the prepared data to train a DecisionTreeClassifier. The code is as follows: Output: precision recall f1-score support
0 0.98 0.98 0.98 966
1 0.89 0.89 0.89 149
accuracy 0.97 1115
macro avg 0.94 0.93 0.94 1115
weighted avg 0.97 0.97 0.97 1115Here we used DecisionTreeClassifier from sklearn to train our model, and the classicfication_metrics() is used for evaluating the predictions. Let’s check the confusion matrix for the decision tree classifier. Output:  Heatmap Advantages and Disadvantages of Decision Tree ClassifierAdvantages of Decision Tree Classifier
Drawbacks of Decision Tree Classifier
ConclusionIn this article, we have explored the world of Decision Tree Classifiers using Scikit-Learn. We have covered the theoretical foundations, implementation, and practical applications of Decision Tree Classifiers, providing a comprehensive guide for both beginners and experienced practitioners. By understanding the strengths and limitations of Decision Tree Classifiers, we can harness their power to build accurate and interpretable machine learning models. |
Reffered: https://www.geeksforgeeks.org
| AI ML DS |
Type: | Geek |
Category: | Coding |
Sub Category: | Tutorial |
Uploaded by: | Admin |
Views: | 17 |