|
|
The Visual Geometry Group (VGG) models, particularly VGG-16 and VGG-19, have significantly influenced the field of computer vision since their inception. These models, introduced by the Visual Geometry Group from the University of Oxford, stood out in the 2014 ImageNet Large Scale Visual Recognition Challenge (ILSVRC) for their deep convolutional neural networks (CNNs) with a uniform architecture. VGG-19, the deeper variant of the VGG models, has garnered considerable attention due to its simplicity and effectiveness. This article delves into the architecture of VGG-19, its evolution, and its impact on the development of deep learning models. Table of Content Evolution of VGG ModelsBefore the advent of VGG models, CNN architectures like LeNet-5 and AlexNet laid the groundwork for deep learning in computer vision. LeNet-5, introduced in the 1990s, was one of the first successful applications of CNNs in recognizing handwritten digits. AlexNet, which won the ILSVRC in 2012, marked a significant breakthrough by leveraging deeper architectures and GPU acceleration. The VGG models were introduced by Karen Simonyan and Andrew Zisserman in their 2014 paper titled “Very Deep Convolutional Networks for Large-Scale Image Recognition.” The primary objective was to investigate the effect of increasing the depth of CNNs on large-scale image recognition tasks. VGG-16 and VGG-19, with 16 and 19 weight layers respectively, were among the most notable models presented in the paper. Their design was characterized by using small 3×3 convolution filters consistently across all layers, which simplified the network structure and improved performance.
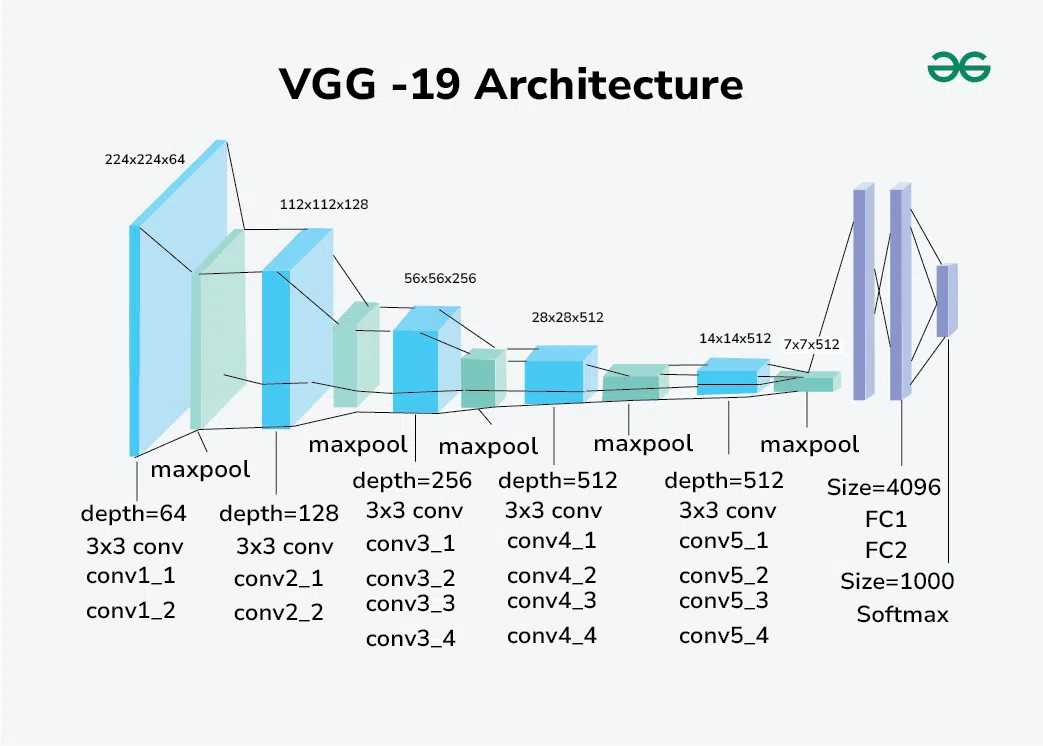
VGG-19 ArchitectureVGG-19 is a deep convolutional neural network with 19 weight layers, comprising 16 convolutional layers and 3 fully connected layers. The architecture follows a straightforward and repetitive pattern, making it easier to understand and implement. The key components of the VGG-19 architecture are:
Detailed Layer-by-Layer Architecture of VGG-Net 19The VGG-19 model consists of five blocks of convolutional layers, followed by three fully connected layers. Here is a detailed breakdown of each block: VGG-19 Architecture Block 1
Block 2
Block 3
Block 4
Block 5
Fully Connected Layers
Architectural Design PrinciplesThe VGG-19 architecture follows several key design principles:
Impact and Legacy of VGG-19Influence on Subsequent ModelsThe simplicity and effectiveness of VGG-19 influenced the design of subsequent deep learning models. Architectures like ResNet and Inception drew inspiration from the depth and uniformity principles established by VGG models. VGG-19’s deep yet straightforward architecture demonstrated that increasing depth could significantly improve performance in image recognition tasks. Use in Transfer LearningVGG-19 has been extensively used in transfer learning due to its robust feature extraction capabilities. Pre-trained VGG-19 models on large datasets like ImageNet are often fine-tuned for various computer vision tasks, including object detection, image segmentation, and style transfer. Research and Industry ApplicationsVGG-19 has found applications in numerous research and industry projects. Its architecture has been used as a baseline in academic research, enabling comparisons with newer models. In industry, VGG-19’s pre-trained weights serve as powerful feature extractors in applications ranging from medical imaging to autonomous vehicles. Additional Information about VGGNet-19
ConclusionIn conclusion, VGG-19 stands as a landmark model in the history of deep learning, combining simplicity with depth to achieve remarkable performance. Its architecture serves as a foundation for many modern neural networks, highlighting the enduring impact of its design principles on the field of computer vision. |
Reffered: https://www.geeksforgeeks.org
| AI ML DS |
Type: | Geek |
Category: | Coding |
Sub Category: | Tutorial |
Uploaded by: | Admin |
Views: | 15 |