|
|
In the field of deep learning, the quest for more efficient neural network architectures has been ongoing. EfficientNet has emerged as a beacon of innovation, offering a holistic solution that balances model complexity with computational efficiency. This article embarks on a detailed journey through the intricate layers of EfficientNet, illuminating its architecture, design philosophy, training methodologies, performance benchmarks, and more. Table of Content EfficientnetEfficientNet is a family of convolutional neural networks (CNNs) that aims to achieve high performance with fewer computational resources compared to previous architectures. It was introduced by Mingxing Tan and Quoc V. Le from Google Research in their 2019 paper “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks.” The core idea behind EfficientNet is a new scaling method that uniformly scales all dimensions of depth, width, and resolution using a compound coefficient. EfficientNet-B0 Architecture OverviewThe EfficientNet-B0 network consists of:
EfficientNet-B0 Detailed ArchitectureEfficientNet uses a technique called compound coefficient to scale up models in a simple but effective manner. Instead of randomly scaling up width, depth, or resolution, compound scaling uniformly scales each dimension with a certain fixed set of scaling coefficients. Using this scaling method and AutoML, the authors of EfficientNet developed seven models of various dimensions, which surpassed the state-of-the-art accuracy of most convolutional neural networks, and with much better efficiency. From the table, the architecture of EfficientNet-B0 can be summarized as follows:
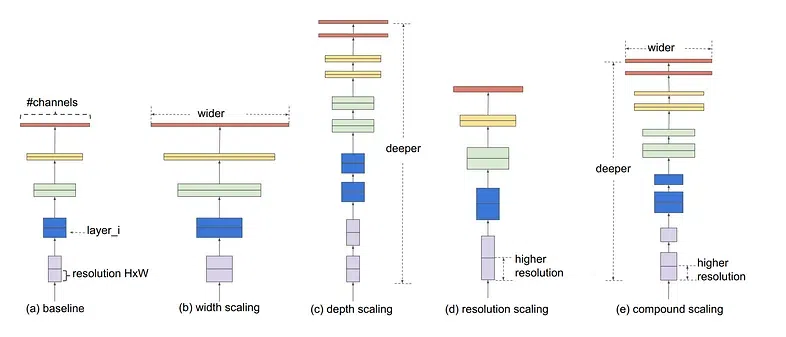
Compound Scaling MethodAt the heart of EfficientNet lies a revolutionary compound scaling method, which orchestrates the simultaneous adjustment of network width, depth, and resolution using a set of fixed scaling coefficients. This approach ensures that the model adapts seamlessly to varying computational constraints while preserving its performance across different scales and tasks. Compound Scaling: The authors thoroughly investigated the effects that every scaling strategy has on the effectiveness and performance of the model before creating the compound scaling method. They came to the conclusion that, although scaling a single dimension can help improve model performance, the best way to increase model performance overall is to balance the scale in all three dimensions (width, depth, and image resolution) while taking the changeable available resources into consideration. The below images show the different methods of scaling:
Different scaling methods vs. Compound scaling This is achieved by uniformly scaling each dimension with a compound coefficient φ. The formula for scaling is:
The principle behind the compound scaling approach is to scale with a constant ratio in order to balance the width, depth, and resolution parameters. Depth-wise Separable ConvolutionEfficientNet uses depth-wise separable convolutions to lower computational complexity without sacrificing representational capability. This is achieved by splitting the normal convolution into two parts:
This makes the network more efficient by requiring fewer computations and parameters. Inverted Residual BlocksInspired by MobileNetV2, EfficientNet employs inverted residual blocks to further optimize resource usage. These blocks start with a lightweight depth-wise convolution followed by point-wise expansion and another depth-wise convolution. Additionally, squeeze-and-excitation (SE) operations are incorporated to enhance feature representation by recalibrating channel-wise responses. 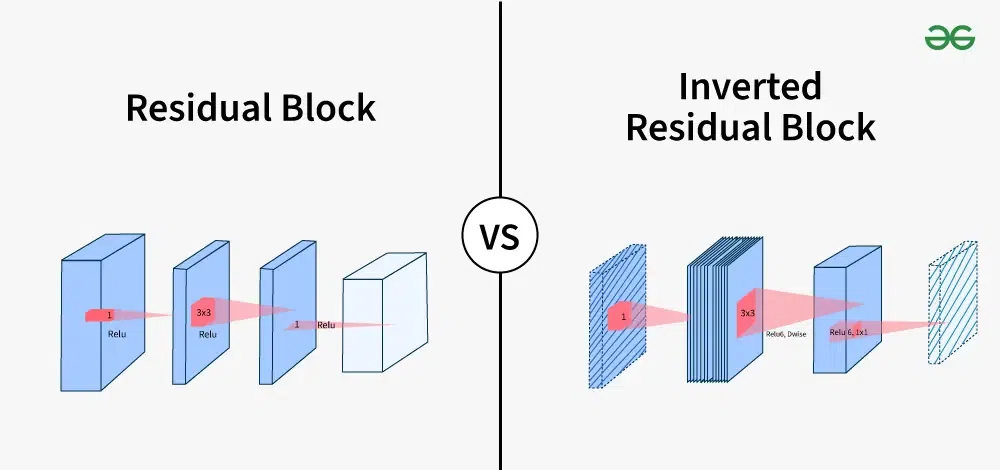
Inverted Residual Block StructureAn inverted residual block follows a narrow -> wide -> narrow structure:
Efficient Scaling:EfficientNet achieves efficient scaling by progressively increasing model depth, width, and resolution based on the compound scaling coefficient φ. This allows for the creation of larger and more powerful models without significantly increasing computational overhead. By carefully balancing these dimensions, EfficientNet achieves state-of-the-art performance while remaining computationally efficient. Efficient Attention Mechanism:EfficientNet incorporates efficient attention mechanisms, such as squeeze-and-excitation (SE) blocks, to improve feature representation. SE blocks selectively amplify informative features by learning channel-wise attention weights. This enhances the discriminative power of the network while minimizing computational overhead. Variants of EfficientNet Model:EfficientNet offers several variants, denoted by scaling coefficients like B0, B1, B2, etc. These variants differ in depth, width, and resolution based on the compound scaling approach. For example:
Each variant of EfficientNet offers a trade-off between model size, computational cost, and performance, catering to various deployment scenarios and resource constraints. Performance Evaluation and ComparisonEvaluating the efficacy of EfficientNet involves subjecting it to various performance benchmarks and comparative analyses. Across multiple benchmark datasets and performance metrics, EfficientNet demonstrates outstanding efficiency, outperforming its predecessors in terms of accuracy, computational cost, and resource utilization. .webp)
For instance, on the ImageNet dataset, the largest EfficientNet model, EfficientNet-B7, achieved approximately 84.4% top-1 and 97.3% top-5 accuracy. Compared to the previous best CNN model, EfficientNet-B7 was 6.1 times faster and 8.4 times smaller in size. On the CIFAR-100 dataset, it achieved 91.7% accuracy, and on the Flowers dataset, 98.8% accuracy. Efficiency and Performance
ConclusionEfficientNet stands as a testament to the ingenuity of modern deep learning architectures. Its scalable design, coupled with efficient training methodologies, positions it as a versatile tool for a myriad of computer vision tasks. As we navigate the ever-expanding landscape of artificial intelligence, EfficientNet serves as a guiding light, illuminating the path towards more efficient and effective neural network designs. FAQs on Efficientnet ArchitectureQ. What sets EfficientNet apart from other neural network architectures?
Q. How does EfficientNet achieve efficiency without compromising performance?
Q. Can EfficientNet be fine-tuned for specific tasks or domains?
Q. Is EfficientNet suitable for real-time applications or resource-constrained environments?
Q. What are some practical applications of EfficientNet in the field of computer vision?
Q. Are there any ongoing research efforts or future developments related to EfficientNet?
|
Reffered: https://www.geeksforgeeks.org
| AI ML DS |
Type: | Geek |
Category: | Coding |
Sub Category: | Tutorial |
Uploaded by: | Admin |
Views: | 15 |