
|
|
This article focuses on discussing how to import SparkSession in Scala. Table of Content What is Sparksession?When spark runs, spark Driver creates a SparkSession which is an entry point to start programming with RDD, DataFrames, and Dataset to connect with Spark Cluster. The Sparksession was introduced in the Spark 2.0 version. It provides an interface for working with structured data processing. Before SparkSession, SparkContext used to be the entry point to run Spark. We must know that SparkSession doesn’t completely replace SparkContext, because SparkSession creates SparkConfig, SparkContext. The APIs that we used earlier in SparkContext like SQLContext, and HiveContext were now used with SparkSession. SparkSession includes the following APIs:
PrerequisitesThe basic prerequisite would be choosing the spark version which is spark 2.0 or higher. The new library org.apache.spark.sql.SparkSession was introduced with all the Contexts that we discussed above. Approach to Import SparkSession in ScalaWe can create SparkSession using spark-shell, Scala, Python. Spark-shell, provides the SparkSession by default and we can run SparkSession with variable spark. In Scala, the SparkSession is created with the following methods:
ImplementationTo import spark session, we use default library ‘org.apache.spark.sql.SparkSession’ using import statement. Let’s create SparkSession in scala as below: Output: SparkSession in Scala Create a DataFrame Using SparkSessionSparkSession has various methods like createDataFrame() used to create a DataFrame from list. Output: 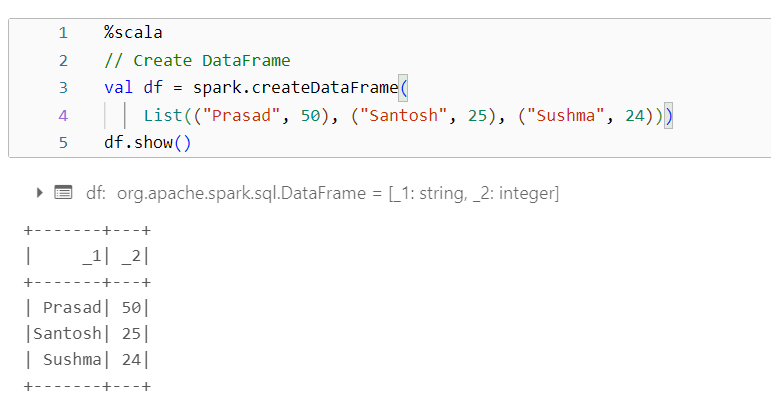 Creating DataFrame in Scala ConclusionSparkSession is a unified entry point for working with structured data in Spark 2.0 and later versions. It combines functionality from SparkContext, SQLContext, and HiveContext. SparkSession is designed for working with DataFrames and Datasets, which offer more structured and optimized operations compared to RDDs. SparkSession supports SQL queries, structured streaming, and DataFrame-based machine learning APIs. In tools like spark-shell and Databricks, the default SparkSession object is available as the spark variable. |
Reffered: https://www.geeksforgeeks.org
| Scala |
Type: | Geek |
Category: | Coding |
Sub Category: | Tutorial |
Uploaded by: | Admin |
Views: | 14 |