|
|
In machine learning, decision trees are a popular tool for making predictions. However, a common problem encountered when using these models is overfitting. Here, we explore overfitting in decision trees and ways to handle this challenge. Why Does Overfitting Occur in Decision Trees?Overfitting in decision tree models occurs when the tree becomes too complex and captures noise or random fluctuations in the training data, rather than learning the underlying patterns that generalize well to unseen data. Other reasons for overfitting include:
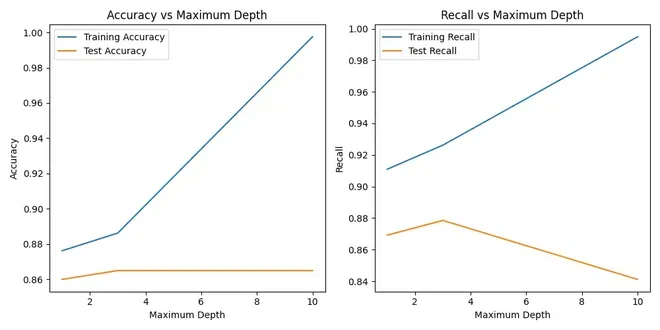
Strategies to Overcome Overfitting in Decision Tree ModelsPruning TechniquesPruning involves removing parts of the decision tree that do not contribute significantly to its predictive power. This helps simplify the model and prevent it from memorizing noise in the training data. Pruning can be achieved through techniques such as cost-complexity pruning, which iteratively removes nodes with the least impact on performance. Limiting Tree DepthSetting a maximum depth for the decision tree restricts the number of levels or branches it can have. This prevents the tree from growing too complex and overfitting to the training data. By limiting the depth, the model becomes more generalized and less likely to capture noise or outliers. Minimum Samples per Leaf NodeSpecifying a minimum number of samples required to create a leaf node ensures that each leaf contains a sufficient amount of data to make meaningful predictions. This helps prevent the model from creating overly specific rules that only apply to a few instances in the training data, reducing overfitting. Feature Selection and EngineeringCarefully selecting relevant features and excluding irrelevant ones is crucial for building a robust model. Feature selection involves choosing the most informative features that contribute to predictive power while discarding redundant or noisy ones. Feature engineering, on the other hand, involves transforming or combining features to create new meaningful variables that improve model performance. Ensemble MethodsEnsemble methods such as Random Forests and Gradient Boosting combine multiple decision trees to reduce overfitting. In Random Forests, each tree is trained on a random subset of the data and features, and predictions are averaged across all trees to improve generalization. Gradient Boosting builds trees sequentially, with each tree correcting the errors of the previous ones, leading to a more accurate and robust model. Cross-ValidationCross-validation is a technique used to evaluate the performance of a model on multiple subsets of the data. By splitting the data into training and validation sets multiple times, training the model on different combinations of data, and evaluating its performance, cross-validation helps ensure that the model generalizes well to unseen data and is not overfitting. Increasing Training DataProviding more diverse and representative training data can help the model learn robust patterns and reduce overfitting. Increasing the size of the training dataset allows the model to capture a broader range of patterns and variations in the data, making it less likely to memorize noise or outliers present in smaller datasets. Handling Overfitting in Decision Tree ModelsIn this section, we aim to employ pruning to reduce the size of decision tree to reduce overfitting in decision tree models. Step 1: Import necessary libraries and generate synthetic dataHere , we generate synthetic data using scikit-learn’s make_classification() function. It then splits the data into training and test sets using train_test_split(). Step 2: Model Training and Initial EvaluationThis function trains a decision tree classifier with a specified maximum depth (or no maximum depth if None is provided) and evaluates it on both training and test sets. It returns the accuracy and recall scores for both sets along with the trained classifier. Step 3: Visualization of Accuracy and RecallHere the decision tree classifiers are trained with different maximum depths specified in the max_depths list. The train_and_evaluate() function is called for each maximum depth, and the accuracy and recall scores along with the trained classifiers are stored for further analysis. Output: Accuracy Recall Plot
Step 5: Pruning Decision TreesThis part introduces cost-complexity pruning, an additional method to optimize decision trees by reducing their complexity after the initial training. It re-evaluates the pruned trees and visualizes their performance compared to the original unpruned trees. Step 6: Comparing Accuracy and Recall before and after PruningOutput: 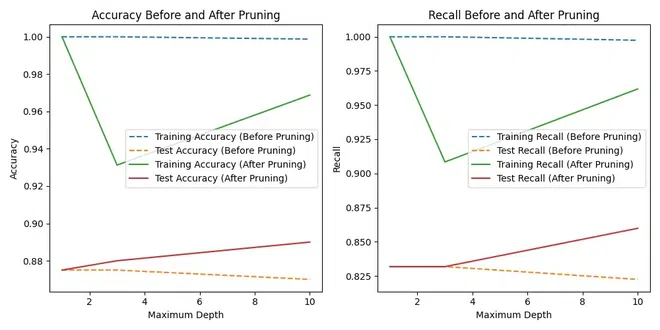 Accuracy Recall Before After Pruning Plot
Step 7: Visualizing ROC curves for Pruned ClassifiersOutput: 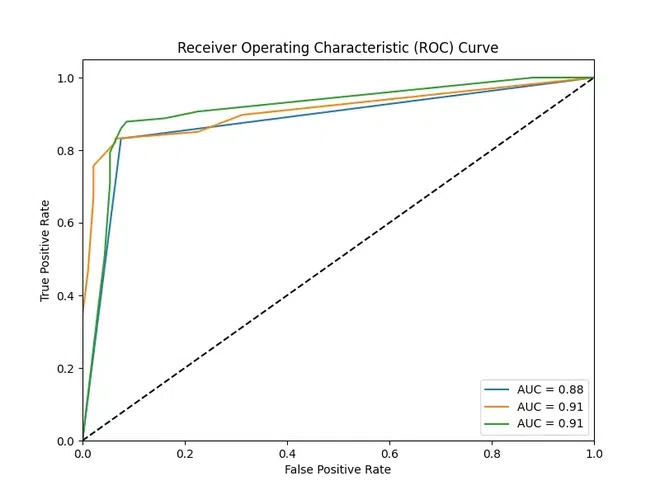 ROC Curve Plot ROC curves for the pruned decision tree classifiers. The plot displays the true positive rate against the false positive rate, and the area under the curve (AUC) is calculated to evaluate the classifier’s performance. ConclusionDecision trees are known for their simplicity in machine learning, yet overfitting causes a common challenge. This occurs when the model learns the training data too well but fails to generalize to new data. The code demonstrates how pruning techniques can address overfitting by simplifying decision trees. By comparing accuracy and recall before and after pruning, the effectiveness of these techniques is evident. Additionally, the recall curve visualization offers insight into the model’s ability to distinguish between positive and negative cases. |
Reffered: https://www.geeksforgeeks.org
| AI ML DS |
| Related |
|---|
| |
| |
| |
| |
| |
Type: | Geek |
Category: | Coding |
Sub Category: | Tutorial |
Uploaded by: | Admin |
Views: | 14 |