
|
|
In MySQL, the two most common ways of managing and retrieving unique values are with SELECT and GROUP BY. However, they are used for different reasons. With SELECT, we can get different values from the same column, so we don’t have to worry about duplicates. With GROUP BY, we can aggregate data and group results based on specific columns. However, there are some differences between the two operators. Both can be used to generate the same output. But we need to know the difference for better utilization of resources and time. SELECT DISTINCTThe SELECT DISTINCT statement is used to retrieve unique values from a single column or a combination of columns in a table. It is often used when you want to eliminate duplicate rows from the result set. Syntax: SELECT DISTINCT column1, column2 Parameters Used:
GROUP BYThe GROUP BY clause is used to group rows that have the same values in specified columns into summary rows, like calculating aggregates (e.g., COUNT, SUM, AVG) for each group. It is typically used with aggregate functions. Syntax: SELECT column1, column2, ..., aggregate_function(column_name) Parameters Used:
Let’s understand the difference between SELECT DISTINCT and GROUP BY through some examples: Example of SELECT DISTINCT vs GROUP BY in MySQLLet’s assume we have a customers table and an orders table. We are going to use these tables to show how DISTINCT and GROUP BY can be used for different use cases: Query:CREATE TABLE customers ( Output:customers table Orders Table Query:CREATE TABLE orders ( Output: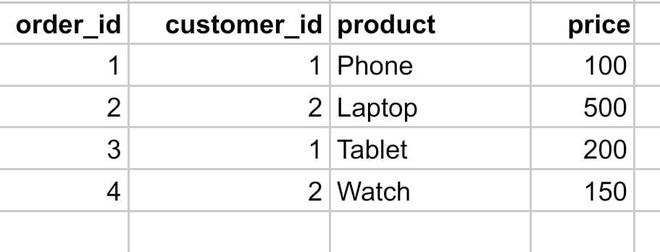 orders table Example 1: Find distinct customer citiesHere, we want to get names of distinct cities only, so DISTINCT will be the obvious choice here. Use SELECT DISTINCT to retrieve unique cities where customers reside: SELECT DISTINCT city Output: Distinct clause output Explanation: The SQL query retrieves unique values from the “city” column in the “customers” table. The output provides a list of distinct cities where customers are located, eliminating duplicate entries and showcasing the unique cities in the dataset. Example 2: Count Orders Per Customer CityHere, we also want to count the number of orders per city. Since an aggregate function(COUNT) is involved here, we will be using GROUP BY. Use GROUP BY to group customers by city and count their orders: SELECT city, COUNT(*) AS order_count Output: order by Explanation: The SQL query joins the “customers” and “orders” tables on the customer_id, grouping the results by city. It counts the number of orders for each city, providing an output that displays the distinct cities along with the corresponding count of orders placed by customers in each city. Key Differences Observed in This Example
Purposes and FunctionalitiesSELECT DISTINCT:
GROUP BY:
Choosing between them
ConclusionIn MySQL, SELECT DISTINCT is used to retrieve unique values from one or more columns in a result set, eliminating duplicates without aggregation. Conversely, GROUP BY is employed to group rows sharing common values in specified columns, enabling aggregation functions to summarize data within each group. While SELECT DISTINCT is suitable for obtaining unique values, GROUP BY is essential for performing complex aggregations and generating summary results based on grouping criteria, each serving distinct purposes in MySQL query operations. |
Reffered: https://www.geeksforgeeks.org
| Databases |
Type: | Geek |
Category: | Coding |
Sub Category: | Tutorial |
Uploaded by: | Admin |
Views: | 11 |