|
|
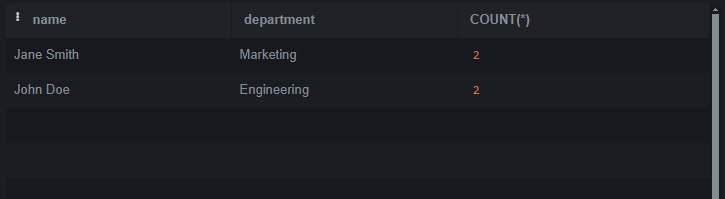
SQLite is a lightweight and open–source relational database management system (RDBMS). SQLite does not require any server to process since it is a serverless architecture that can run operations and queries without any server. In this article, we will understand how to remove duplicate rows except one row. We will also see some techniques which help us to remove duplicate rows. Introduction to Duplicate Rows in SQLiteDuplicate rows refer to entries within a database table that share identical values across all columns or a subset of columns. These duplicates can arise due to various reasons, such as data entry errors, data migration issues, or database design problems. Setting Up EnvironmentLet’s create a table called employees and insert some data also to better understand. Query: CREATE TABLE employees Let’s insert some data into the Employees table. Copy code Identifying Duplicate RowsBefore start removing, it is important to identify which rows are duplicates. It can be done using SQLite’s GROUP BY and HAVING clauses in conjunction with aggregate functions like COUNT(). Let’s run basic query to identify duplicates in the employees table Query: SELECT name, department, COUNT(*) Output: OUTPUT Explanation: In the above query we selects rows from the Ways to Removing Duplicate RowsWhen an duplicates records are identified or verified then the next step to retain only one instance of each duplicated row and removing the others. SQLite offers multiple method to solve this which include help of ROWID, temporary tables, subqueries, and Common Table Expressions (CTEs). Let’s understand each one of them with the help of example. Method 1: Using ROWIDROWID is a special column that exists in every ordinary table. It’s an implicit column that serves as the Primary key for the table if we have not explicitly defined one. It provides a convenient way to uniquely identify rows in a table which is essential to understand its working. SQLite automatically assigns a unique ROWID to each row of every table which can be easy to identify and remove duplicates. Query: DELETE FROM employees Output: 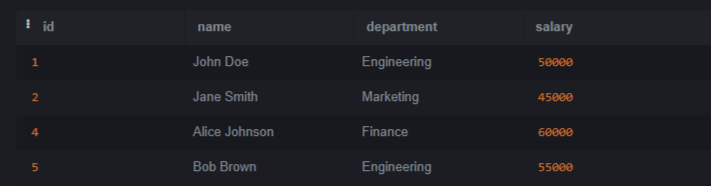 OUTPUT Explanation: After executing the query, the duplicate rows will be removed from the employees table, retaining only one instance of each unique row. Method 2: Using Temporary TableAnother approach involves creating a temporary table to store unique rows and then replacing the original table. Query: CREATE TABLE temp_employees AS Output: 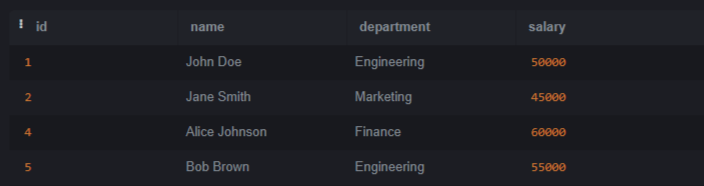 OUTPUT Explanation: After executing these commands, the employees table will have duplicate rows removed, preserve only one instance of each unique row. Method 3: Using SubquerySubquery is also known as a nested query or inner query. It is a query which is nested within another query. It allows us to perform more complex operations by using the result of one query as input for another query. Using a subquery, We can select the distinct rows and then delete the remaining duplicates from the original table. Query: DELETE FROM employees Output: 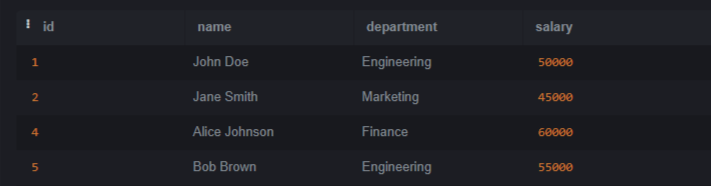 OUTPUT Explanation: After executing the query, duplicate rows will be removed from the employees table, reserve only one instance of each unique row. Method 4: Using Common Table Expressions (CTEs)Common Table Expressions (CTEs) provide a way to define temporary result sets within a query. These result sets defined by a CTE can be used within the same query similar like subquery. CTEs increase the readability and maintainability for complex queries that require multiple levels of nesting. Common Table Expressions (CTEs) offer a convenient way to define temporary result sets that can be referenced within a statement. We can use CTEs to identify and remove duplicates. Query: WITH duplicates AS Output: 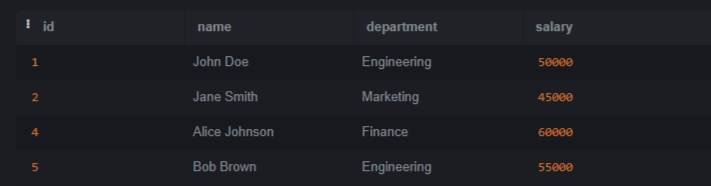 OUTPUT Explanation: After executing the query the duplicate rows will be deleted from the employees table preserve only one instance of each unique row based on the specified columns. ConclusionOverall, After reading whole article now we have good understanding of how to identify duplicate rows and also how to delete them. We can remove duplicate rows with the help of one of them method which is described above. The method we have discussed which are ROWID, temporary tables, subqueries, and Common Table Expressions (CTEs). The Duplicate rows in database is important to remove to maintain data integrity and optimizing performance. |
Reffered: https://www.geeksforgeeks.org
| Databases |
Type: | Geek |
Category: | Coding |
Sub Category: | Tutorial |
Uploaded by: | Admin |
Views: | 12 |