|
|
Semantic similarity is the similarity between two words or two sentences/phrase/text. It measures how close or how different the two pieces of word or text are in terms of their meaning and context. In this article, we will focus on how the semantic similarity between two sentences is derived. We will cover the following most used models.
What is Semantic Similarity?Semantic Similarity refers to the degree of similarity between the words. The focus is on the structure and lexical resemblance of words and phrases. Semantic similarity delves into the understanding and meaning of the content. The aim of the similarity is to measure how closely related or analogous the concepts, ideas, or information conveyed in two texts are. In NLP semantic similarity is used in various tasks such as
There are certain approaches for measuring semantic similarity in natural language processing (NLP) that include word embeddings, sentence embeddings, and transformer models. Word EmbeddingTo understand semantic relationships between sentences one must be aware of the word embeddings. Word embeddings are used for vectorized representation of words. The simplest form of word embedding is a one-hot vector. However, these are sparse, very high dimensional, and do not capture meaning. The more advanced form consists of the Word2Vec (skip-gram, cbow), GloVe, and Fasttext which capture semantic information in low dimensional space. Kindly look at the embedded link to get a deeper understanding of this. Word2VecWord2Vec represents the words as high-dimensional vectors so that we get semantically similar words close to each other in the vector space. There are two main architectures for Word2Vec:
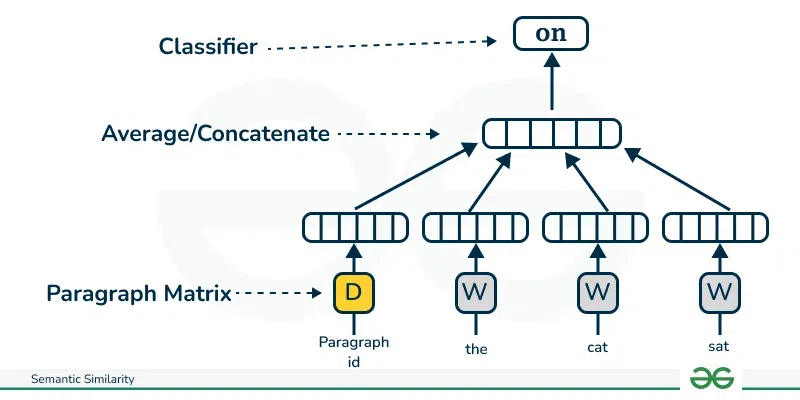
Doc2VecSimilar to word2vec Doc2Vec has two types of models based on skip gram and CBOW. We will look at the skip gram-based model as this model performs better than the cbow-based model. This skip-gram-based model is called ad PV-DM (Distributed Memory Model of Paragraph Vectors). PV-DM model PV-DM is an extension of Word2Vec in the sense that it consists of one paragraph vector in addition to the word vectors.
In summary, the algorithm itself has two key stages:
We use the learned paragraph vectors to predict some particular labels using a standard classifier, e.g., logistic regression. Python Implementation of Doc2VecBelow is the simple implementation of Doc2Vec.
Python3
Output: Original Document: The baby was laughing and palying
Document 2: Similarity Score: 0.9838361740112305
Document Text: The baby learned to walk in the 5th month itself
Document 0: Similarity Score: 0.9455077648162842
Document Text: The movie is awesome. It was a good thriller
Document 1: Similarity Score: 0.8828089833259583
Document Text: We are learning NLP throughg GeeksforGeeksSBERTSBERT adds a pooling operation to the output of BERT to derive a fixed-sized sentence embedding. The sentence is converted into word embedding and passed through a BERT network to get the context vector. Researchers experimented with different pooling options but found that at the mean pooling works the best. The context vector is then averaged out to get the sentence embeddings. SBERT uses three objective functions to update the weights of the BERT model. The Bert model is structured differently based on the type of training data that drives the objective function. 1. Classification objective Function
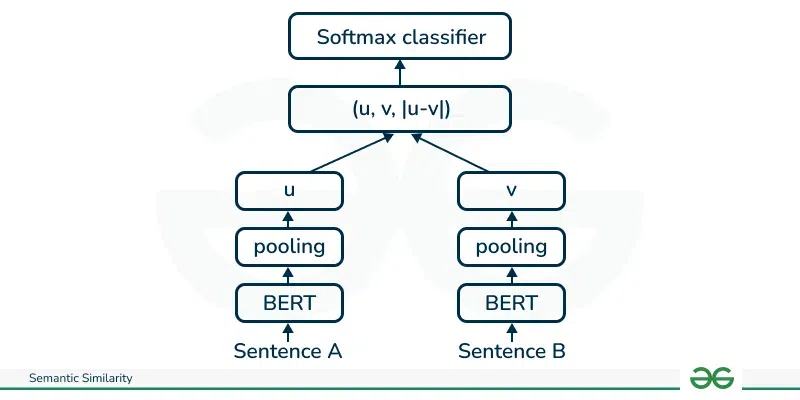 SBERT with Classification Objective Function 2. Regression Objective functionThis also uses the pair of sentences with labels as training data. The network is also structured as a Siamese network. However, instead of the softmax layer the output of the pooling layer is used to calculate cosine similarity and mean squared-error loss is used as the objective function to train the BERT model weights.  SBERT with Regression Objective Function 3. Triplet objective functionHere the model is structured as triplet networks.
Mathematically, we minimize the following loss function.
Python ImplementationTo implement it first we need to install Sentence transformer framework !pip install -U sentence-transformers
Python3
Output: Test sentence: I liked the movie. InferSentThe structure comprises two components: Sentence Encoder
Classifier
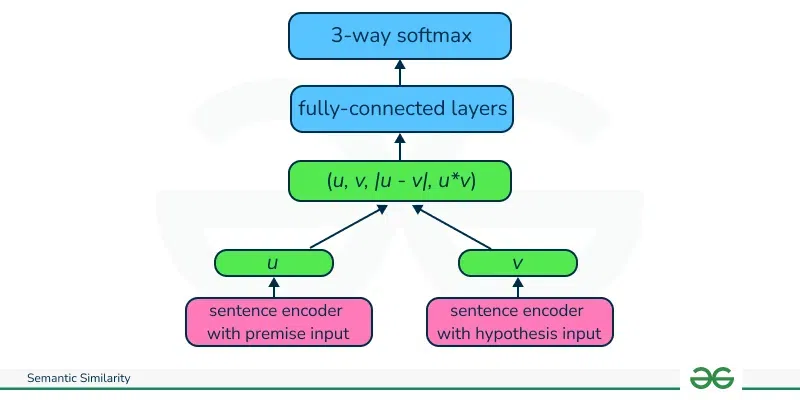 Training Sentence Encoder for Classification Python ImplementationImplementing an infersent model is a bit lengthy process as there is no standard hugging face API available. Infersent comes traiend in two version. Version1 is trained with Glove and Version2 is trained with FastText wordembedding. We will use version 2 as it takes less time to download and process. First, we need to build the infersent model. The below class does that. It has been sourced from Python Zoo model. Python3
Next, we download the state-of-the-art fastText embeddings and download the pre-trained models. Python3
Python3
Python3
Output: Test Sentence: I liked the movie USE – Universal Sentence EncoderAt a high level, it consists of an encoder that summarizes any sentence to give a sentence embedding which can be used for any NLP task. The encoder part comes in two forms and either of them can be used
Training of the USE The USE is trained on a variety of unsupervised and supervised tasks such as Skipthoughts, NLI, and more using the below principles.
 Training of Encoder Python ImplementationWe load the Universal Sentence Encoder’s TF Hub module.
Python3
Python3
Output Test Sentence: ['I liked the movie very much'] ConclusionIn this article we understood semantic similarity and its application. We saw the architecture of top 4 sentence embedding models used for semantic similarity calculation of sentences and their implementation in python. |


Reffered: https://www.geeksforgeeks.org
| AI ML DS |

Type: | Geek |
Category: | Coding |
Sub Category: | Tutorial |
Uploaded by: | Admin |
Views: | 13 |