|
|
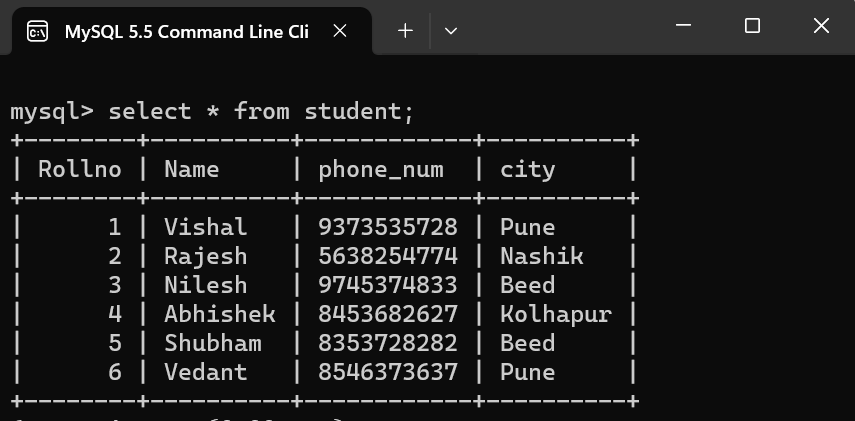
MySQL, like many relational database management systems, provides powerful tools for manipulating and analyzing data through the use of SQL (Structured Query Language). Two commonly used clauses, GROUP BY and PARTITION BY, play essential roles in aggregate queries and window functions, respectively. In this article, we are going to learn about the differences between the GROUP BY and PARTITION BY clauses in MySQL. Database and Table CreationFor better understanding let’s take an example by creating the database and table, created using the following commands: 1. To create the database CREATE DATABASE School; 2. To show the all databases on the machine SHOW DATABASES; 3. To select the database on which you have to work USE School; 4. To create the table in the Database CREATE TABLE student ( 5. To insert the data in the table INSERT INTO student VALUES (1, 'Vishal', '9373533572', 'Pune'); Do same for the insert the data in the table. 6. For showing the table SELECT * FROM student; Then the below will be the Structure of the table student Table GROUP BYThe GROUP BY clause is a fundamental component of SQL queries when working with aggregated data. Its primary purpose is to group rows based on common values in specified columns, allowing the application of aggregate functions to each group independently. Syntax:
where,
Example of the GROUP BY ClauseUse the GROUP BY clause using the following command on student table: SELECT city, count(*) Output: 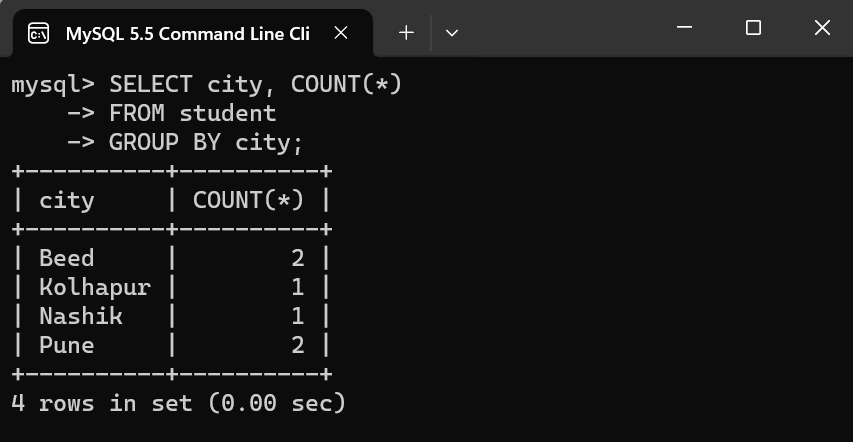 output Explanation: In this result, the count column is labeled as COUNT(*), which is the default label for the count function in a SELECT statement. This result indicates the count of students in each city based on the provided data. PARTITION BYIn MySQL, the PARTITION BY clause is used in the context of window functions, also known as analytic functions. Window functions operate on a set of rows related to the current row, allowing for more complex and fine-grained calculations. Syntax:
Where,
Example of the PARTITION BY ClauseUse the GROUP BY clause using the following command on student table: SELECT Below is the output for the above query: Output: 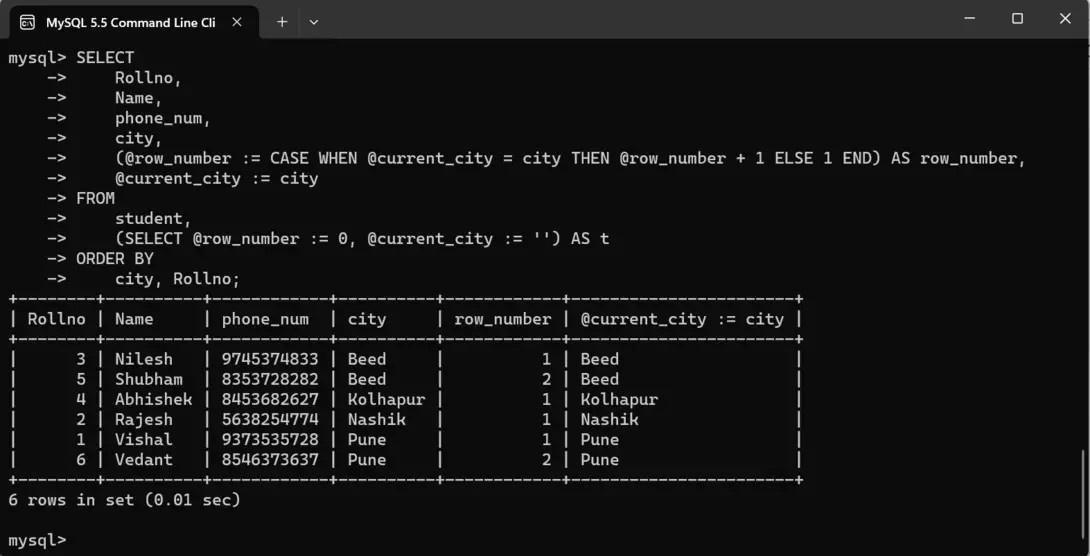 output Explanation: We’re using user-defined variables @row_number and @current_city to keep track of the row number and the current city, respectively. For each row, we check if the current city is the same as the previous row’s city. If it is, we increment the row number. Otherwise, we reset the row number to 1. We use the ORDER BY clause to ensure that rows are ordered by city and then by Rollno. This query will assign a row number to each record within each city, ordered by the Rollno. Key Differences Between GROUP BY and PARTITION BY
ConclusionWhile both GROUP BY and PARTITION BY are essential tools in SQL, they serve distinct purposes. GROUP BY is geared towards aggregating data and creating summary statistics, making it indispensable for reporting and analytics. PARTITION BY, on the other hand, enhances the capabilities of window functions, providing a way to perform complex calculations within specific partitions of the result set. Understanding the distinctions between these clauses allows SQL developers to leverage their full potential in crafting efficient and insightful queries. |
Reffered: https://www.geeksforgeeks.org
| Databases |
Type: | Geek |
Category: | Coding |
Sub Category: | Tutorial |
Uploaded by: | Admin |
Views: | 13 |