|
|
Word2Vec is a modeling technique used to create word embeddings. It creates a vector of words where it assigns a number to each of the words. Word embeddings generally predict the context of the sentence and predict the next word that can occur. In R Programming Language Word2Vec provides two methods to predict it:
The basic idea of word embedding is words that occur in similar contexts tend to be closer to each other in vector space. The vectors are used as input to do specific NLP tasks. The other tasks are text summarization, text matching, etc. Continuous Bag of WordsThe continuous Bag of Words (CBOW) model aims to predict the target word based on the context provided by the surrounding words. The working of the CBOW is as follows:
CBOW is adjusted using the neural network to minimize the difference between the predicted word and the actual word in the target. CBOW
Ouput: The output should predict the word “nice”.
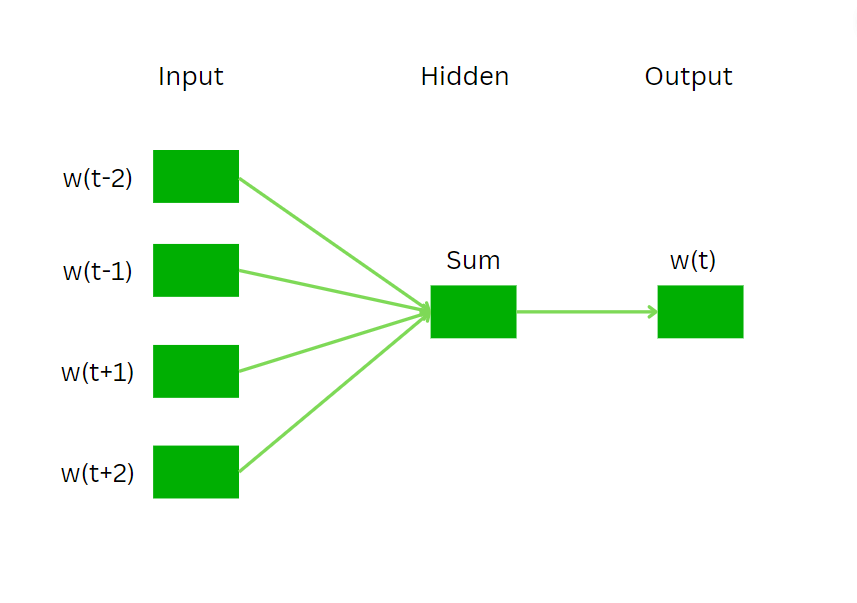
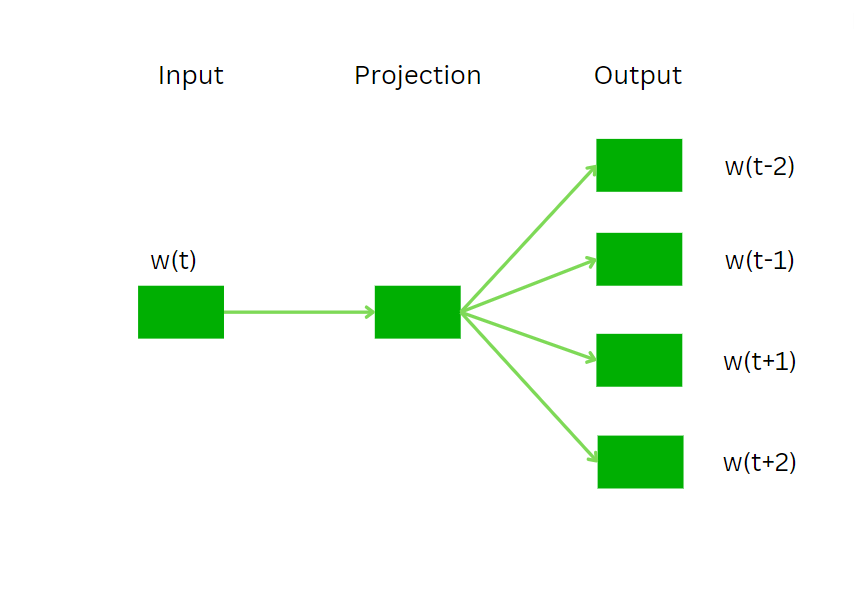
Skip GramSkip-Gram predicts the context words based on the given target word, contrary to CBOW which predicts the target word. It learns the relationships between words by training the model maximizing the probability of predicting context words given a target word. The working of Skip gram is as follows:
Skip-gram is trained by adjusting the weights of the neural network to maximize the likelihood of predicting the correct context words from the embedding layer.
For the chosen target word (“nice”), an embedding layer is created representing the word as a vector in a high-dimensional space. The dimensions of this vector are determined by the chosen embedding size during the model training.
Continuous Bag of Words for lookalike wordsIn this example, we load the word2vec library which allows to train a model for word 2 vector and use cbow and skip gram algorithms. We can train model, see embeddings and see nearest words to any word. Dataset drive link: BRAirlines Dataset Step 1: Import the libraries word2vec for training the cbow model and data.table for dataframe. R
Step 2: Import the dataset. We will be using Airline reviews as our dataset provided in kaggle. R
Step 3: Create the cbow model with the reviews and provide dimension of 15 and maximum iterations 20. R
Step 4: Find the similar context words that are nearest in meaning by using the predict() method and provide the type as nearest. R
Output: [1] "The nearest words for hotel and airbus in CBOW model prediction is as follows "
$hotel
term1 term2 similarity rank
1 hotel taxi 0.9038663 1
2 hotel destination 0.8645503 2
3 hotel bag 0.8606780 3
4 hotel neck 0.8571329 4
5 hotel clothes 0.8561315 5
$airbus
term1 term2 similarity rank
1 airbus ordeal 0.8780979 1
2 airbus equally 0.8745981 2
3 airbus uneventful 0.8690495 3
4 airbus BAH 0.8677440 4
5 airbus beers 0.8504817 5
Step 5: Find the embeddings of some words as follows by using the predict() method and provide the type as embedding. R
Output: [1] "The CBOW embedding for airbus and plane is as follows "
[,1] [,2] [,3] [,4] [,5] [,6]
airbus 0.1426127 0.2532609 -0.6377366 0.02548989 1.6425037 -0.3880948
plane -0.6500510 -0.4534873 1.1207893 0.50630522 0.3934476 -1.0468076
[,7] [,8] [,9] [,10] [,11] [,12]
airbus 1.4523754 1.51974189 -0.1617979 2.170428 0.147469506 0.1358749
plane -0.2956116 0.07400164 1.0075779 1.670310 0.004237913 -0.5283979
[,13] [,14] [,15]
airbus -0.2461894 -0.6237084 -1.419138
plane -1.3195559 -0.8242296 -2.238492
Visualizing the Embeddings in the CBOW ModelHere we will visualize the word embeddings and how the words correlate with each other. Step 1: Create a corpus of the reviews. R
Step 2: Apply some preprocessing for the text to extract the list of words and split them. R
Step 3: Now we convert it to Document Term Matrix. Next we split the words and extract them. R
Step 4: We take a list of 100 words from it. R
Step 5: Get the embeddings for the words and drop which dont have embeddings using the na.omit() method. We use the predict() method with type embedding to get the embeddings. It stores the words with there embeddings. R
Step 6: Since the embeddings are high dimensional array, we first scale down it and then plot it using plotly for interactive plotting. For lowering the dimension we use the umap() method from umap library. We provide n_neighbors for how many neighbours to consider as the reduced dimension for this task. R
Output: Skip Gram Embeddings and lookalike wordsStep 1: Import the libraries word2vec for training the skip-gram model and data.table for dataframe. R
Step 2: Import the dataset. We will be using Airline reviews as our dataset provided in kaggle. R
Step 3: Create the skip-gram model with the reviews and provide dimension of 15 and maximum iterations 20. R
Step 4: Create embeddings using the predict() method provided by word2vec model. Then print the embeddings of any word. R
Output: [1] "The SKIP Gram embedding for airbus and plane is as follows "
[,1] [,2] [,3] [,4] [,5] [,6]
airbus -0.2280359 -0.06950876 -0.8975230 0.2383098 0.9572678 1.3951594
plane -0.8150198 -0.25508881 -0.2011317 0.6494479 1.1521208 0.6378013
[,7] [,8] [,9] [,10] [,11] [,12] [,13]
airbus 0.1191502 -1.828172 -0.1717374 0.4359438 0.1890430 2.530286 -1.072369
plane 0.3009279 -1.175530 -0.9957678 0.9003520 0.2462102 1.611048 -1.707145
[,14] [,15]
airbus 0.1053236 0.207101
plane -1.1464180 1.383812
Step 5: Find the similar context words that are nearest in meaning by using the predict() method and provide the type as nearest. R
Output:
[1] "The nearest words for hotel and airbus in skip gram model \nprediction is as follows "
$hotel
term1 term2 similarity rank
1 hotel accommodation 0.9651411 1
2 hotel destination 0.9277243 2
3 hotel cab 0.9195876 3
4 hotel taxi 0.9188855 4
5 hotel transportation 0.9100887 5
$airbus
term1 term2 similarity rank
1 airbus airplane 0.9217460 1
2 airbus slight 0.9211015 2
3 airbus itself 0.9184811 3
4 airbus parked 0.8968953 4
5 airbus Trip 0.8923244 5
Step 6: Create new embeddings for the words_list. And then draw the visualization. R
Output: 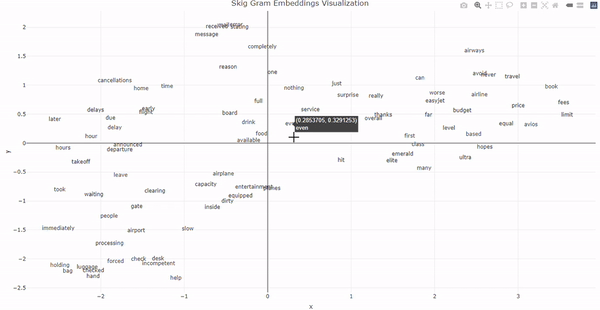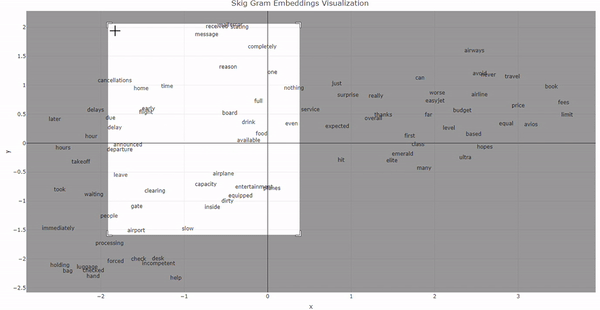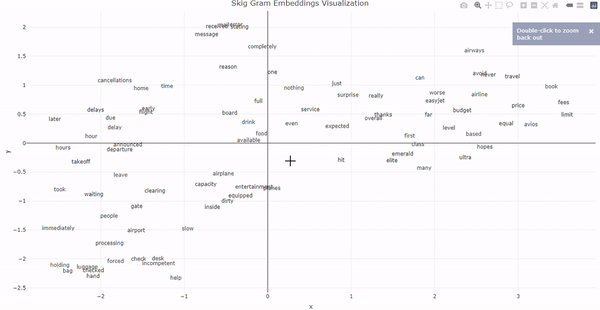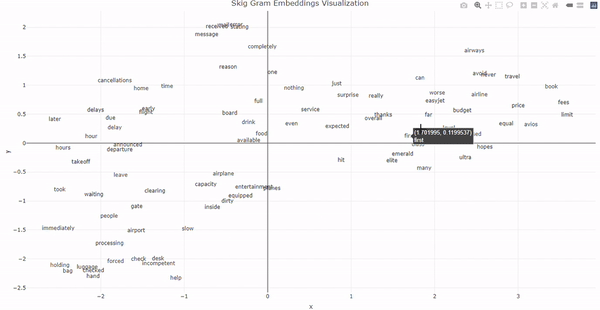 Word2Vec Using R ConclusionIn conclusion, Word2Vec, employing CBOW and Skip-Gram models, generates powerful word embeddings by capturing semantic relationships. CBOW predicts a target word from its context, while Skip-Gram predicts context words from a target word. These embeddings enable NLP tasks and, as demonstrated with airline reviews, showcase the models’ ability to find contextually similar words. |

Reffered: https://www.geeksforgeeks.org
| AI ML DS |

Type: | Geek |
Category: | Coding |
Sub Category: | Tutorial |
Uploaded by: | Admin |
Views: | 15 |