
|
|
In this article, we are going to see how to utilize Pandas DataFrame and series for data wrangling. The process of cleansing and integrating dirty and complicated data sets for easy access and analysis is known as data wrangling. As the amount of data raises continually and expands, it is becoming more important to organize vast amounts of data for analysis. Data wrangling comprises activities such as data sorting, data filtering, data reduction, data access, and data processing. Data wrangling is one of the most important tasks in data science and data analysis. Let’s see how to utilize Pandas DataFrame and series for data wrangling. Utilize series for data wranglingCreating Seriespd.Series() method is used to create a pandas Series. In this, a list is given as an argument and we use the index parameter to set the index of the Series. The index helps us to retrieve data based on conditions. Python3
Output:
Filtering data- Retrieving insights based on conditions from the dataFrom the previous data, we retrieve data on two conditions, one is the population of India and another is countries that have a population of more than a billion. Python3
Output: 
We can also use dictionaries to create Series in python. In this, we have to pass a Dictionary as an argument in the pd.Series() method. Python3
Output:
Changing indices by altering the index of seriesIn pd.Series the index can be manipulated or altered by specifying a new index series. Python3
Output: 
Utilize Pandas Dataframe for data wranglingCreating Dataframe using CSVIn this example, we will use a CSV file to print top n (5 by default) rows of a DataFrame or series using the Pandas.head() method. Python3
Output: 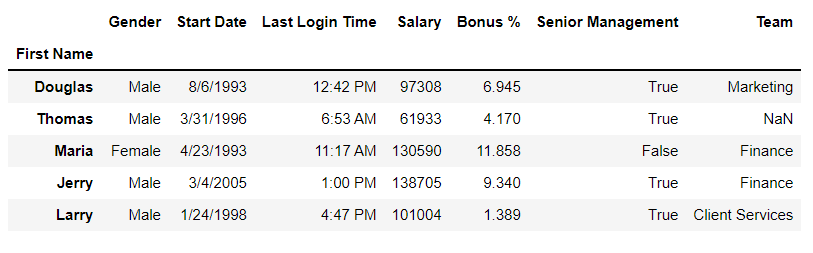
Describing DataFramepd.Describe() method is used to get the summary statistics of the Dataframe. Python3
Output: 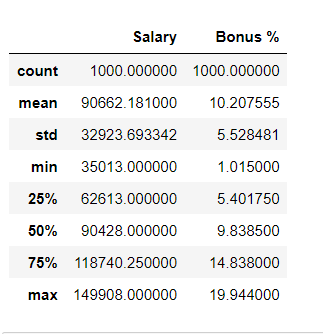
Setting and Resetting the index of the Dataframepd.set_index is used for setting and resetting the index of the Dataframe. Whereas, pd.reset_index() reverts the Dataframe back to the normal state. Here, the name of the column is given as an argument. Example 1: Resetting the index of the Dataframe in Start Date columns Python3
Output: 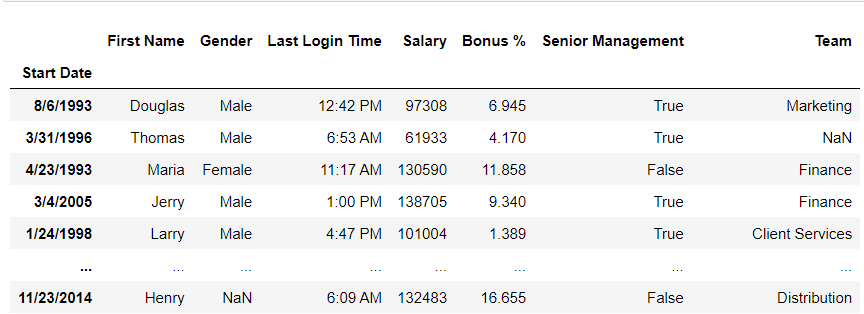
Example 2: Resetting the index of the Dataframe in First Name columns Python3
Output: 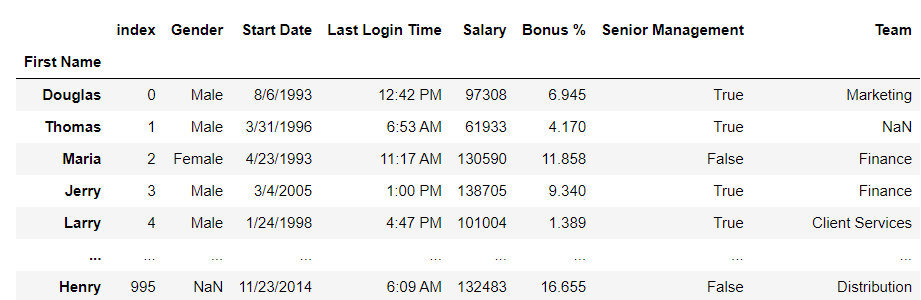
Deleting a column from the DataFramesThe column ‘Salary’ is deleted from the DataFrames from our CSV file. Python3
Output: 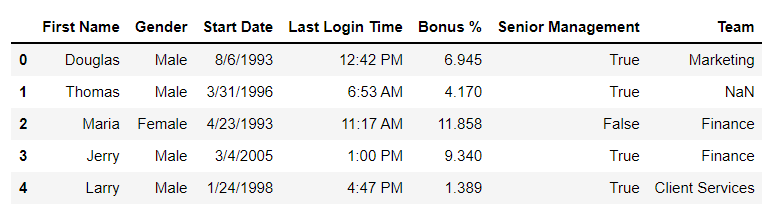
Reshaping dataframedf.Transpose() function is used to find the transpose of the given DataFrame. Python3
Output: 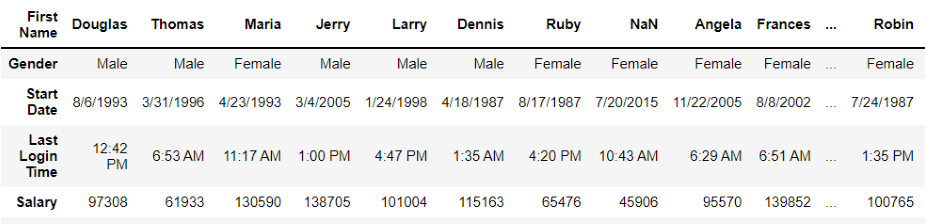
Sorting the Dataframedf.sort_values() function is used to sort data. In this, the column name is passed as a parameter. Python3
Output: 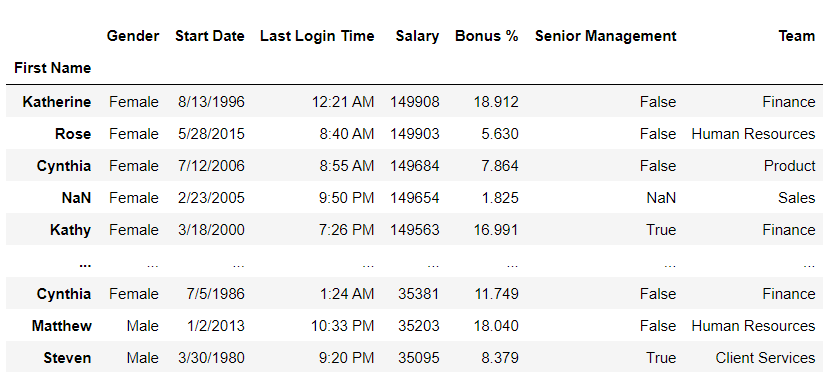
Dealing with missing valuesMissing or null values can be checked with the Pandas df.null() method. Python3
Output: 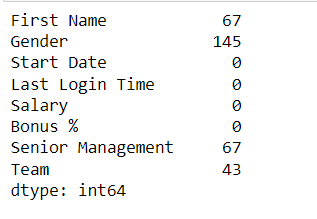
Dropping RowsWe can filter rows that have null values by using df.dropna() method. Python3
Output: 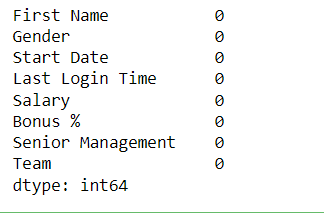
Grouping DataIn Data Analysis, the Grouping of data sets is a common requirement when the outcome must be expressed in terms of many groups. Panadas provides us with a built-in mechanism for grouping data into several categories. The pandas‘ df.groupby() technique is used for grouping data. In the below code, We will create a DataFrames of students and their grades. In this groupby() method is used to group students according to their grades with their names. Python3
Output: 
Merging DataframePandas df.merge() method is used to merge two DataFrames. There are different ways of merging DataFrames like, outer join, inner join, left join, right join, etc. Python3
Output: 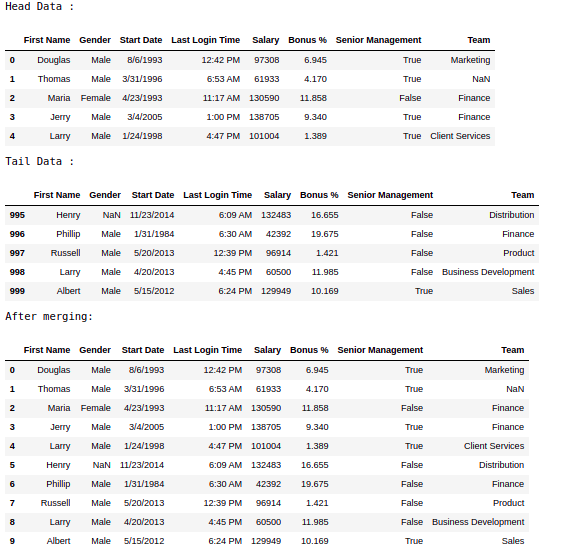
Concatenating DataThe Concat function is used to conduct concatenation operations along an axis. Let’s create two DataFrames and concatenate them. Python3
Output: 
|
Reffered: https://www.geeksforgeeks.org
| Geeks Premier League |
Type: | Geek |
Category: | Coding |
Sub Category: | Tutorial |
Uploaded by: | Admin |
Views: | 12 |