|
|
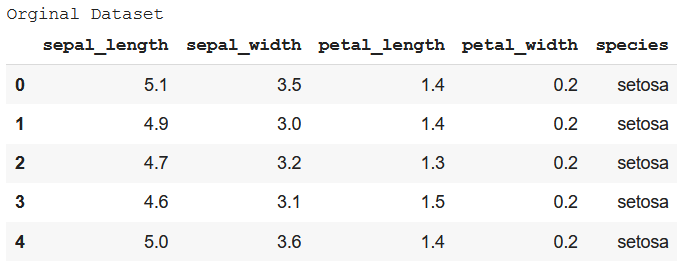
When a dataset has values of different columns at drastically different scales, it gets tough to analyze the trends and patterns and comparison of the features or columns. So, in cases where all the columns have a significant difference in their scales, are needed to be modified in such a way that all those values fall into the same scale. This process is called Scaling. There are two most common techniques of how to scale columns of Pandas dataframe – Min-Max Normalization and Standardization. Both of them have been discussed in the content below. Dataset in Use: Iris Min-Max NormalizationHere, all the values are scaled in between the range of [0,1] where 0 is the minimum value and 1 is the maximum value. The formula for Min-Max Normalization is –
Method 1: Using Pandas and Numpy The first way of doing this is by separately calculate the values required as given in the formula and then apply it to the dataset. Example: Python3
Output: 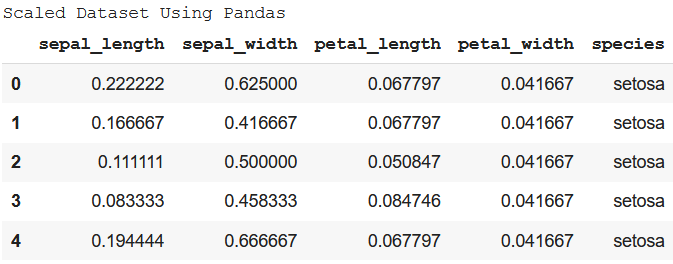
Method 2: Using MinMaxScaler from sklearn This is a straightforward method of doing the same. It just requires sklearn module to be imported. Example: Python3
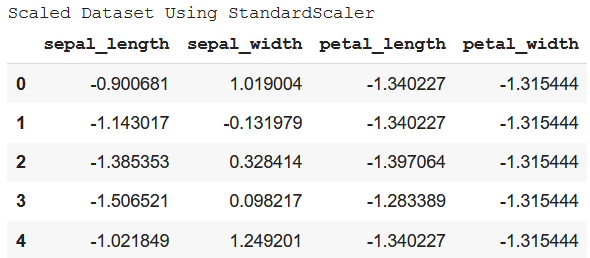
Output: 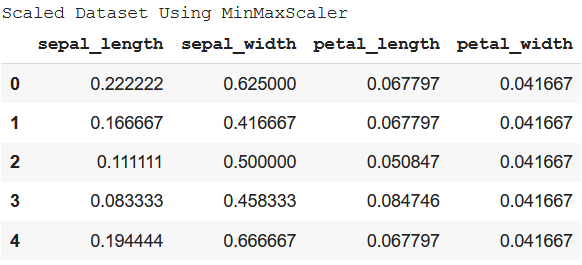 StandardizationStandardization doesn’t have any fixed minimum or maximum value. Here, the values of all the columns are scaled in such a way that they all have a mean equal to 0 and standard deviation equal to 1. This scaling technique works well with outliers. Thus, this technique is preferred if outliers are present in the dataset. Example: Python3
Output :
|

Reffered: https://www.geeksforgeeks.org
| Python |
Type: | Geek |
Category: | Coding |
Sub Category: | Tutorial |
Uploaded by: | Admin |
Views: | 7 |