|
|
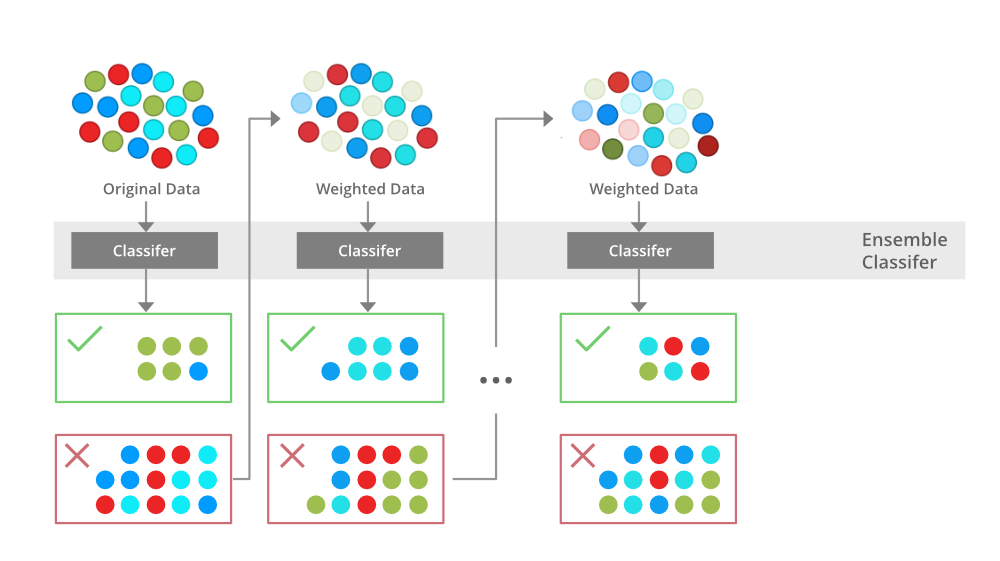
In this article, we will learn about the AdaBoost classifier and its practical implementation over a dataset.AdaBoost algorithm falls under ensemble boosting techniques, as we will discuss it combines multiple models to produce more accurate results and this is done in two phases:
Note: For more information, refer Boosting ensemble models What is AdaBoostAdaBoost short for Adaptive Boosting is an ensemble learning used in machine learning for classification and regression problems. The main idea behind AdaBoost is to iteratively train the weak classifier on the training dataset with each successive classifier giving more weightage to the data points that are misclassified. The final AdaBoost model is decided by combining all the weak classifier that has been used for training with the weightage given to the models according to their accuracies. The weak model which has the highest accuracy is given the highest weightage while the model which has the lowest accuracy is given a lower weightage. Institution Behind AdaBost AlgorithmAdaBoost techniques combine many weak machine-learning models to create a powerful classification model for the output. The steps to build and combine these models are as Step1 – Initialize the weights
Step2 – Train weak classifiers
Step3 – Calculate the error rate and importance of each weak model Mk
Step4 – Update data point weight for each data point Wi
Step5 – Normalize the Instance weight
Step6 – Repeat steps 2-5 for K iterations
Boosting Algorithms Python implementation of AdaBoostPython provides special packages for applying AdaBoost we will see how we can use Python for applying AdaBoost on a machine learning problem. In this problem, we are given a dataset containing 3 species of flowers and the features of these flowers such as sepal length, sepal width, petal length, and petal width, and we have to classify the flowers into these species. Import LibrariesLet’s begin with importing important libraries that we will require to do our classification task: Reading And Describing The DatasetAfter, importing the libraries we will load our dataset using the pandas read_csv method as: (150, 6) We can see our dataset contains 150 rows and 6 columns. Let us take a look at our actual content in the dataset using head() method as:
Dropping Irrevelant Column and Separating Target VariableThe first column is the Id column which has no relevance to flowers so, we will drop it using drop() function. The Species column is our target feature and tells us about the species the flowers belong to. We will separate it using pandas iloc slicing. Shape of X is (150, 4) and shape of y is (150,) Unique values in our Target VariableSince this is a classification task we will see the numbers of categories we want to classify our dataset input vector into. Number of unique species in dataset are: 3 Iris-virginica 50 Iris-setosa 50 Iris-versicolor 50 Name: Species, dtype: int64 Let’s dig deep into our dataset, and we can see in the above image that our dataset contains 3 classes into which our flowers are distributed also since we have 150 samples all three species have an equal number of samples in the dataset, so we have no class imbalance. Splitting The DatasetNow, we will split the dataset for training and validation purposes, the validation set is 25% of the total dataset. For dividing the dataset into training and testing we will use train_test_split method from the sklearn model selection. Applying AdaBoostAfter creating the training and validation set we will build our AdaBoost classifier model and fit it over the training set for learning. To fit our AdaBoost model we need our dependent variable y and independent variable x. Accuracy of the AdaBoost ModelAs we fit our model on the train set, we will check the accuracy of our model on the validation set. To check the accuracy of the model we will use the validation dataset that we have created using the train_test_split method. The accuracy of the model on validation set is 0.9210526315789473 As we can see the model has an accuracy of 92% on the validation set which is quite good with no hyperparameter tuning and feature engineering. |
Reffered: https://www.geeksforgeeks.org
| Machine Learning |
| Related |
|---|
 Grey wolf optimization - Introduction
Grey wolf optimization - Introduction |
 Weibull Hazard Plot
Weibull Hazard Plot |
| |
| |
 Test of Multicollinearity
Test of Multicollinearity |
Type: | Geek |
Category: | Coding |
Sub Category: | Tutorial |
Uploaded by: | Admin |
Views: | 10 |