
|
|
Let’s take a look at hearing and a case study of selective attention in the context of a crowded cocktail party. Assume you’re at a social gathering with a large number of people speaking at the same time. You’re also talking with a friend, but the background noise is not recognized. You are only paying attention to your friend’s voice and grasping their words while filtering out background noise. In this scenario, our auditory system employs selective attention to focus on the relevant auditory information. The neurological system of our brain improves the representation of speech by prioritizing relevant sounds and ignoring background noises. A computer method for prioritizing specific information in a given context is called the attention mechanism of deep learning. During translation or question-answering activities, attention is used in natural language processing to align pertinent portions of the source phrase. Without necessarily relying on reinforcement learning, attention mechanisms allow neural networks to give various weights to various input items, boosting their ability to capture crucial information and improve performance in a variety of tasks. Google Streetview’s house number identification is an example of an attention mechanism in Computer vision that enables models to systematically identify particular portions of an image for processing. Attention MechanismAn attention mechanism is an Encoder-Decoder kind of neural network architecture that allows the model to focus on specific sections of the input while executing a task. It dynamically assigns weights to different elements in the input, indicating their relative importance or relevance. By incorporating attention, the model can selectively attend to and process the most relevant information, capturing dependencies and relationships within the data. This mechanism is particularly valuable in tasks involving sequential or structured data, such as natural language processing or computer vision, as it enables the model to effectively handle long-range dependencies and improve performance by selectively attending to important features or contexts. Recurrent models of visual attention use reinforcement learning to focus attention on key areas of the image. A recurrent neural network governs the peek network, which dynamically selects particular locations for exploration over time. In classification tasks, this method outperforms convolutional neural networks. Additionally, this framework goes beyond image identification and may be used for a variety of visual reinforcement learning applications, such as helping robots choose behaviours to accomplish particular goals. Although the most basic use of this strategy is supervised learning, the use of reinforcement learning permits more adaptable and flexible decision-making based on feedback from past glances and rewards earned throughout the learning process. The application of attention mechanisms to image captioning has substantially enhanced the quality and accuracy of generated captions. By incorporating attention, the model learns to focus on pertinent image regions while creating each caption word. The model can synchronize the visual and textual modalities by paying attention to various areas of the image at each time step thanks to the attention mechanism. By focusing on important objects or areas in the image, the model is able to produce captions that are more detailed and contextually appropriate. The attention-based image captioning models have proven to perform better at catching minute details, managing complicated scenes, and delivering cohesive and educational captions that closely match the visual material. The attention mechanism is a technique used in machine learning and natural language processing to increase model accuracy by focusing on relevant data. It enables the model to focus on certain areas of the input data, giving more weight to crucial features and disregarding unimportant ones. Each input attribute is given a weight based on how important it is to the output in order to accomplish this. The performance of tasks requiring the utilization of the attention mechanism has significantly improved in areas including speech recognition, image captioning, and machine translation. How Attention Mechanism WorksAn attention mechanism in a neural network model typically consists of the following steps:
By incorporating an attention mechanism, the model can effectively capture dependencies, emphasize important information, and adaptively focus on different elements of the input, leading to improved performance in tasks such as machine translation, text summarization, or image recognition. Attention Mechanism Architecture for Machine TranslationThe attention mechanism architecture in machine translation involves three main components: Encoder, Attention, and Decoder. The Encoder processes the input sequence and generates hidden states. The Attention component computes the relevance between the current target hidden state and the encoder’s hidden states, generating attention weights. These weights are used to compute a context vector that captures the relevant information from the encoder’s hidden states. Finally, the Decoder takes the context vector and generates the output sequence. This architecture allows the model to focus on different parts of the input sequence during the translation process, improving the alignment and quality of the translations. We can observe 3 sub-parts or components of the Attention Mechanism architecture :
Consider the following Encoder-Decoder architecture with Attention. 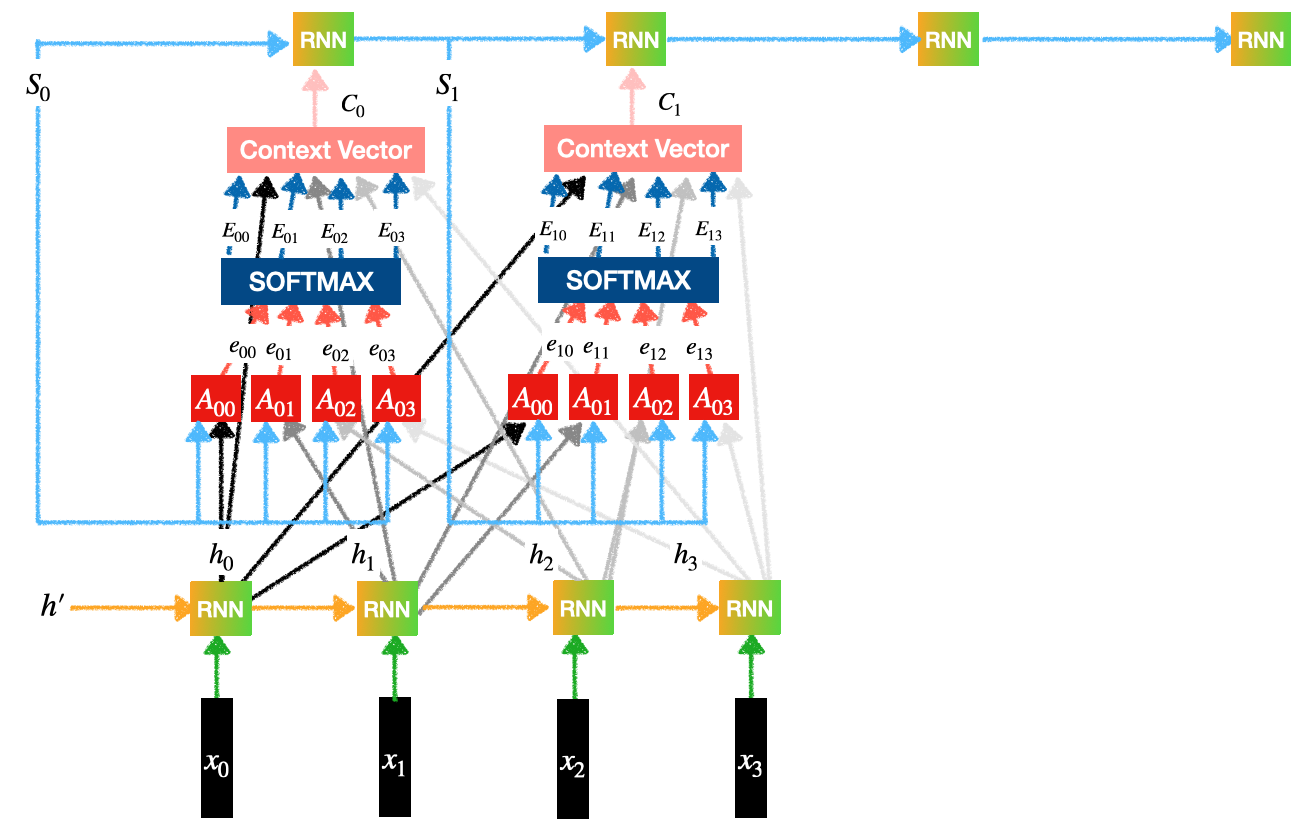 Encoder-Decoder with Attention Encoder:The encoder applies recurrent neural networks (RNNs) or transformer-based models to iteratively process the input sequence. The encoder creates a hidden state at each step that contains the data from the previous hidden state and the current input token. The complete input sequence is represented by these hidden states taken together. 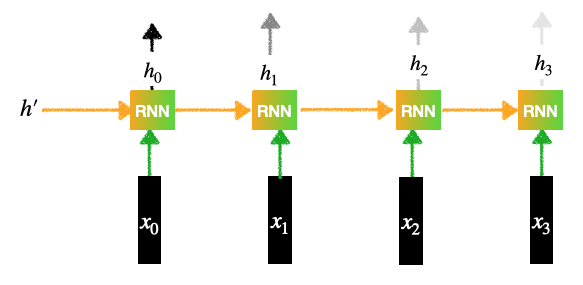 Encoder Contains an RNN layer (Can be LSTMs or GRU):
Attention:The attention component computes the importance or relevance of each encoder’s hidden state with respect to the current target hidden state. It generates a context vector that captures the relevant information from the encoder’s hidden states. The attention mechanism can be represented mathematically as follows:
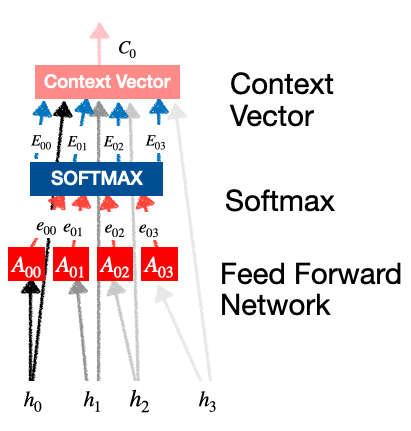 attention Feed Forward Network:The feed-forward network is responsible for transforming the target hidden state into a representation that is compatible with the attention mechanism. It takes the target hidden state h(t-1) and applies a linear transformation followed by a non-linear activation function (e.g., ReLU) to obtain a new representation 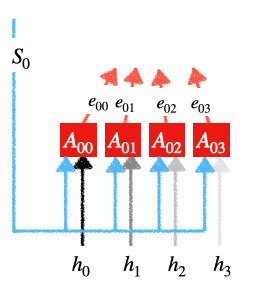 Feed-Forward-Network Each
Each unit generates outputs:
Here,
Attention Weights or Softmax Calculation:A softmax function is then used to convert the similarity scores into attention weights. These weights govern the importance or attention given to each encoder’s hidden state. Higher weights indicate higher relevance or importance. 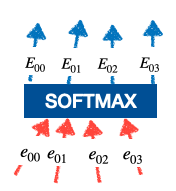 softmax calculation
These Contact Vector Generation:Context Vector: The context vector is a weighted sum of the encoder’s hidden states, where the attention weights serve as the weights for the summation. It represents a specific arrangement of the encoder’s hidden states pertinent to generating the current token. 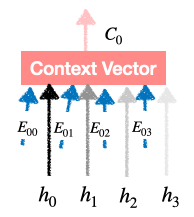 context vector generation
We find Decoder:The context vector is fed into the decoder along with the current hidden state of the decoder in order to predict the next token in the output sequence. Until the decoder generates the entire output sequence, this process is done recursively. We feed these Context Vectors to the RNNs of the Decoder layer. Each decoder produces an output which is the translation for the input words. ConclusionsThe attention mechanism allows the decoder to dynamically focus on different segments of the input sequence based on their importance to the current decoding step. As a result, the model can handle lengthy input sequences with ease and capture the dependencies between various input and output sequence components. The attention mechanism is a crucial component of many cutting-edge sequence-to-sequence models since it significantly boosts the quality and fluency of the generated sequences. Frequently Asked Questions (FAQs)1. What is self attention?
2. What is the applications of attention mechanism?
3. What are the different types of attention mechanism?
4. What are the two main steps of attention mechanism?
5. How attention mechanism works?
|
![Score(s,i) = \left\{\begin{matrix} h_s^{(1)}\cdot y_i & \text{Dot Product} \\ (h_s^{(2)})^TW y_i & \text{General}\\ v^{T}\tanh\left(W \left[ \frac{h_s}{y_i}\right ]\right) & \text{concat} \end{matrix}\right.](https://quicklatex.com/cache3/7e/ql_e7bb06451888d8999205c0adf957e67e_l3.png "Rendered by QuickLaTeX.com")













Reffered: https://www.geeksforgeeks.org
| AI ML DS |

Type: | Geek |
Category: | Coding |
Sub Category: | Tutorial |
Uploaded by: | Admin |
Views: | 14 |