|
|
ChatGPT, developed by OpenAI, represents a significant leap in the field of conversational AI. It is based on the Generative Pre-trained Transformer (GPT) architecture, specifically GPT-3.5, and is designed to generate human-like text based on the input it receives. This article delves into the architecture of ChatGPT, exploring its underlying mechanisms, components, and functionalities, and aims to provide a thorough understanding of how it operates and its potential applications. Table of Content Overview of GPT ArchitectureThe GPT architecture is a type of transformer model that relies heavily on the attention mechanism. Transformers have revolutionized natural language processing (NLP) due to their ability to handle long-range dependencies in text and their efficiency in training on large datasets. GPT models, including ChatGPT, are based on this architecture but are pre-trained on extensive text data and fine-tuned for specific tasks. Historical ContextThe journey of transformer models began with the paper “Attention is All You Need,” which introduced the transformer architecture. Unlike recurrent neural networks (RNNs) and long short-term memory (LSTM) networks, transformers do not process data sequentially. This non-sequential processing allows transformers to be more efficient and effective in capturing dependencies in data. Evolution of ChatGPTThe development of ChatGPT has seen significant advancements over the years, from its initial inception to its current state. Here, we trace the evolution of ChatGPT through its various iterations.
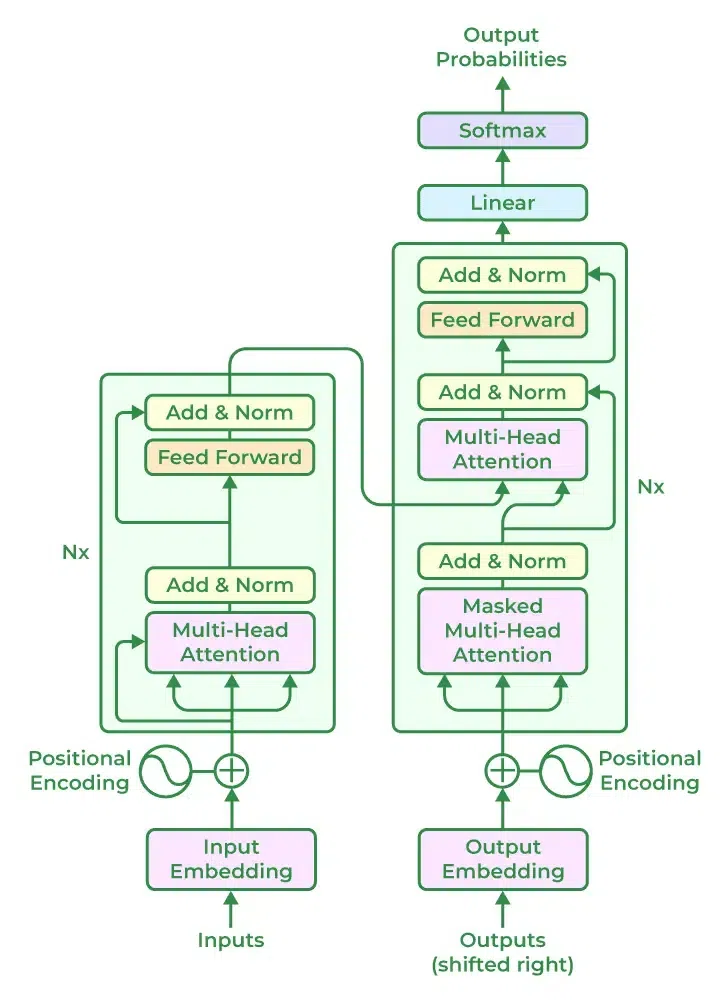
Key Components of ChatGPT1. Transformer BlocksAt the core of ChatGPT are multiple transformer blocks. Each block consists of two main sub-layers:
2. Positional EncodingUnlike recurrent neural networks (RNNs), transformers do not process data sequentially. To capture the order of words, ChatGPT uses positional encoding, which adds information about the position of each token in the sequence. This helps the model understand the context better. 3. Pre-training and Fine-tuningChatGPT undergoes a two-step training process:
Detailed Working and Architecture of ChatGPT1. Input ProcessingThe input text is tokenized into smaller units called tokens. These tokens are then converted into embeddings, which are dense vector representations of the tokens. Positional encodings are added to these embeddings to retain the sequence information. 2. Transformer LayersChatGPT consists of multiple stacked transformer layers. Each layer has two main components:
Transformer Architecture Attention MechanismThe attention mechanism is the backbone of ChatGPT’s ability to understand and generate text. It involves:
3. Output GenerationAfter passing through the transformer layers, the final hidden states are used to generate the output tokens. The model uses a softmax layer to predict the probability distribution over the vocabulary for the next token, generating text step-by-step. 4. Self-Attention in DepthSelf-attention allows each word to look at every other word in the sentence, enabling the model to determine the relevance of other words to the current word. This mechanism helps the model capture nuances and relationships in the text, leading to more coherent and contextually appropriate responses. Reinforcement Learning and ChatGPTReinforcement learning (RL) plays a crucial role in fine-tuning ChatGPT, particularly in aligning the model with human preferences and ethical guidelines. This section explores how RL is integrated into ChatGPT’s development. Reinforcement Learning from Human Feedback (RLHF)OpenAI employs a technique called Reinforcement Learning from Human Feedback (RLHF) to fine-tune ChatGPT. In this approach, human reviewers rank the outputs of the model based on their quality and alignment with desired behaviors. These rankings are then used to train a reward model, which guides the model towards generating more appropriate and contextually relevant responses. Training Process
Benefits of RLHF
ConclusionChatGPT’s architecture, grounded in the powerful GPT framework, showcases the potential of transformer models in conversational AI. By leveraging the attention mechanism, extensive pre-training, and fine-tuning, ChatGPT achieves remarkable performance in generating human-like text. As advancements continue, ChatGPT and its successors are poised to become even more integral to various domains, transforming the way we interact with machines. |
Reffered: https://www.geeksforgeeks.org
| AI ML DS |
| Related |
|---|
| |
| |
| |
| |
| |
Type: | Geek |
Category: | Coding |
Sub Category: | Tutorial |
Uploaded by: | Admin |
Views: | 17 |