|
|
Clustering is a fundamental concept in data analysis and machine learning, where the goal is to group similar data points into clusters based on their characteristics. One of the most critical aspects of clustering is the choice of distance measure, which determines how similar or dissimilar two data points are. In this article, we will explore and delve into the world of clustering distance measures, exploring the different types, and their applications. Table of Content Why Distance Measures Matter?Distance measures are the backbone of clustering algorithms. Distance measures are mathematical functions that determine how similar or different two data points are. The choice of distance measure can significantly impact the clustering results, as it influences the shape and structure of the clusters. The choice of distance measure significantly impacts the quality of the clusters formed and the insights derived from them. A well-chosen distance measure can lead to meaningful clusters that reveal hidden patterns in the data, while a poorly chosen measure can result in clusters that are misleading or irrelevant.
Common Distance MeasuresThere are several types of distance measures, each with its strengths and weaknesses. Here are some of the most commonly used distance measures in clustering: 1. Euclidean DistanceThe Euclidean distance is the most widely used distance measure in clustering. It calculates the straight-line distance between two points in n-dimensional space. The formula for Euclidean distance is: [Tex]d(p,q)=\sqrt[]{\Sigma^{n}_{i=1}{(p_i-q_i)^2}}[/Tex] where,
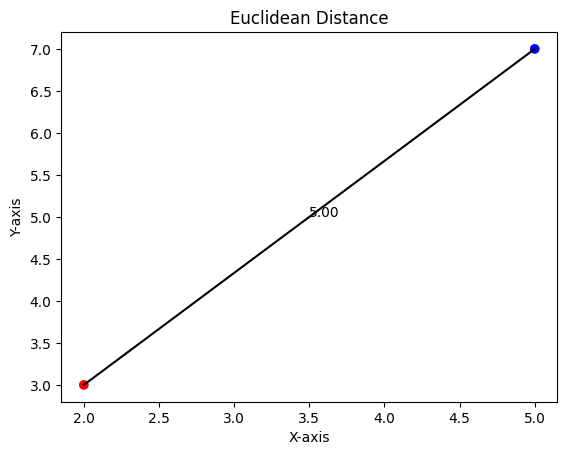
Utilizing Euclidean DistanceOutput: Euclidean Distance: 5.0
Euclidean Distance The two spots that we are computing the Euclidean distance between are represented by the red and blue dots in the figure. The Euclidean distance, represented by the black line that separates them is the distance measured in a straight line. 2. Manhattan DistanceThe Manhattan distance, is the total of the absolute differences between their Cartesian coordinates, sometimes referred to as the L1 distance or city block distance. Envision maneuvering across a city grid in which your only directions are horizontal and vertical. The Manhattan distance, which computes the total distance traveled along each dimension to reach a different data point represents this movement. When it comes to categorical data this metric is more effective than Euclidean distance since it is less susceptible to outliers. The formula is: [Tex]d(p,q)={\Sigma^{n}_{i=1}|p_i-q_i|}[/Tex] Implementation in PythonOutput: Manhattan Distance: 7
.png) Manhattan Distance The two points are represented by the red and blue points in the plot. The grid-line-based method used to determine the Manhattan distance is depicted by the dashed black lines. 3. Cosine SimilarityInstead than concentrating on the exact distance between data points , cosine similarity measure looks at their orientation. It calculates the cosine of the angle between two data points, with a higher cosine value indicating greater similarity. This measure is often used for text data analysis, where the order of features (words in a sentence) might not be as crucial as their presence. It is used to determine how similar the vectors are, irrespective of their magnitude. [Tex]{similarity(A,B)}=\frac{A.B}{\|A\|\|B\|}[/Tex] Example in PythonOutput: Cosine Similarity: 0.9994801143396996
In the plot, the red and blue arrows represent the vectors of the two points from the origin. The cosine similarity is related to the angle between these vectors. 4. Minkowski DistanceMinkowski distance is a generalized form of both Euclidean and Manhattan distances, controlled by a parameter p. The Minkowski distance allows adjusting the power parameter (p). When p=1, it’s equivalent to Manhattan distance; when p=2, it’s Euclidean distance. [Tex]d(x,y)=(\Sigma{^{n}_{i=1}}|x_i-y_i|^p)^\frac{1}{p}[/Tex] Utilizing Minkowski DistanceOutput: Minkowski Distance (p=3): 4.497941445275415
.png) Minkowski Distance In the plot, the visualization is similar to Euclidean distance when p=3, but the distance calculation formula changes. 5. Jaccard IndexThis measure is ideal for binary data, where features can only take values of 0 or 1. It calculates the ratio of the number of features shared by two data points to the total number of features. Jaccard Index measures the similarity between two sets by comparing the size of their intersection and union. [Tex]J(A,B)=\frac{|A\cap B|}{|A\cup B|}[/Tex] Jaccard Index Example in PythonOutput: Jaccard Index: 0.6666666666666666 Choosing the Optimal Distance Metric for Clustering: Key ConsiderationsThe type of data and the particulars of the clustering operation will determine which distance metric is best. Here are some things to think about:
Choosing the Right Distance MeasureThe choice of distance measure depends on the nature of the data and the clustering algorithm being used. Here are some general guidelines:
ConclusionDistance measures are the backbone of clustering algorithms. It is essential to comprehend clustering distance measurements in order to analyze data effectively. You can improve your clustering algorithms accuracy and insights by using the right distance measure. Understanding how to quantify similarity will have a big influence on your outcomes whether you’re working with text, photos , or quantitative data. Remember these ideas and methods as you investigate clustering further to help you make wise choices and get better results for your data science endeavors. |
.png)
Reffered: https://www.geeksforgeeks.org
| AI ML DS |
Type: | Geek |
Category: | Coding |
Sub Category: | Tutorial |
Uploaded by: | Admin |
Views: | 15 |