|
|
Effectively representing textual data is crucial for training models in Machine Learning. The Bag-of-Words (BOW) model serves this purpose by transforming text into numerical form. This article comprehensively explores the Bag-of-Words model, elucidating its fundamental concepts and utility in text representation for Machine Learning. What is Bag-of-Words?Bag-of-words is useful for representing textual data in a passage when using text for training and modelling in Machine Learning. We represent the text in the form of numbers generally in Machine Learning. BOW allows to extract features from text using numerous ways to convert text into numbers. It provides two main features:
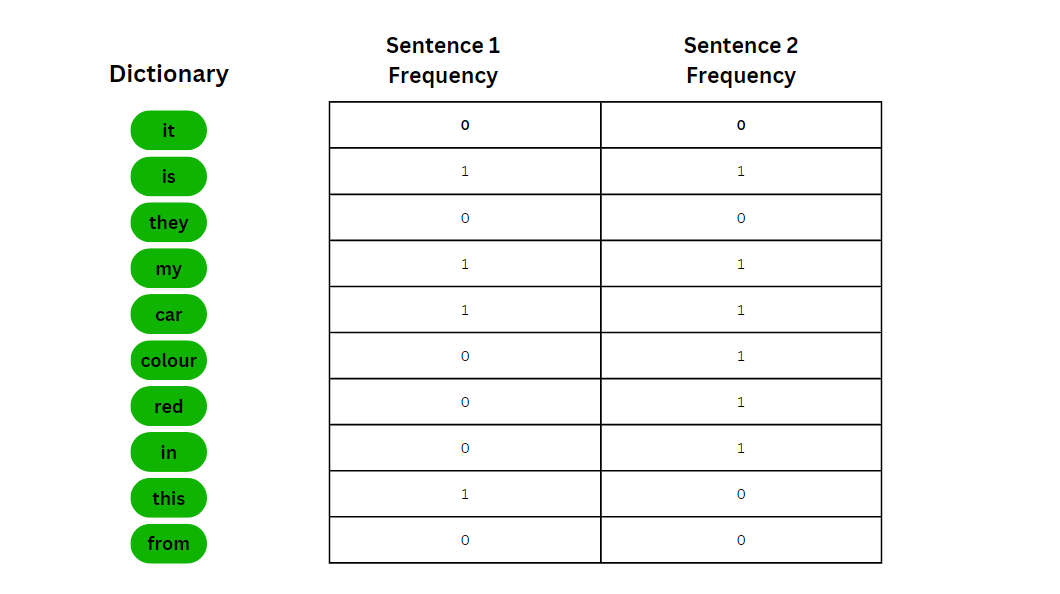
With the help of a bag of words, we can detect the type of document, useful for sentimental analysis, document classification, and spam filtering. The BOW model treats each sentence as a vector, where each element of the vector corresponds to the frequency of a word in the dictionary converting a collection of text documents into a matrix, where each row represents a document, and each column represents a unique word. But, BOW does not preserve the structure of sentences or consider word order. It treats each word as independent, ignoring semantic relationships. Bag-of-Words ExampleSuppose we have the following two sentences:
So we would have a dictionary of some words and we track the frequency of words of each sentence.
With the frequency table, we can feed this vector into machine learning models and train them. Text Classification using Bag of WordsWe will be using the CSV file of Poems from poetryfoundation.org from kaggle.com. Step 1: Install the libraries install.packages("data.table") Step 2: Import the data R
Preprocessing of DataBefore moving ahead, a text needs to be preprocessed before moving ahead. Here are two texts, for eg:
First sentence contains lot of unnecessary characters which can make the model inaccurate. However the second sentence is quite perfect, still the comma, question mark is not required. Punctuation generally don’t add much information, similarly the case. Second is stopwords. These words such as “and”, “in”, “on”, “the” don’t add much information and can skew the model. Hence we need to remove such words. Step 3: Preprocess the data. It includes:
We will be using tm and slam used for text mining and matrix usage. R
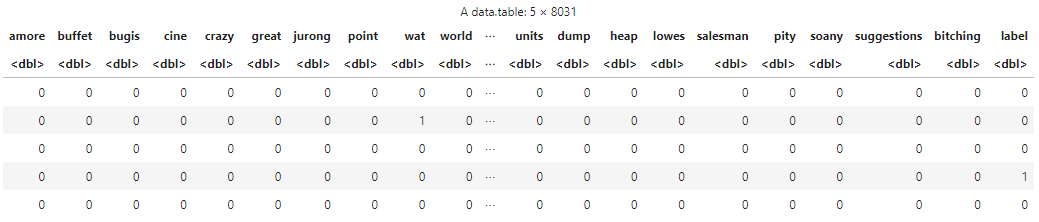
Document-Term MatrixIt is the frequency table with each document on one axis, and dictionary on the other. We will create a matrix using the DocumentTermMatrix method by passing the data corpus and then convert the object into matrix. R
Output:
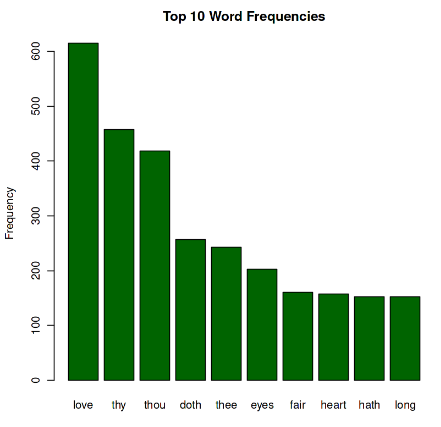
Step 4: First sum the columns of each word and then check the top ten words R
Output:
Step 5: We can also plot the word frequencies using barplot R
Output:
Bag-Of-Words Model In RIn the following example, we use spam email dataset for the classification using bag of words. We use SVM classifier for classification of spam and ham(original). Step 1: Load all required libraries R
Step 2: Load the dataset and preprocess the dataset similar to that of previous example R
Output:
Step 3: Perform the train test split in the ration of 80% 20% for train and test set respectively. R
Step 4: Train the model and create predictions. Then create confusion matrix R
Output: binary_predictions 0 1 Hence, The model has a high accuracy of approximately 97.85%, indicating that it correctly predicts the class for a large proportion of instances. Limitations to Bag-of-Words
ConclusionIn conclusion, Bag-of-Words stands as a versatile tool for converting textual data into a format suitable for machine learning applications. While it excels in certain scenarios, its limitations, such as the loss of sequence information and sparse dataset creation, should be considered. |

Reffered: https://www.geeksforgeeks.org
| Geeks Premier League |
Type: | Geek |
Category: | Coding |
Sub Category: | Tutorial |
Uploaded by: | Admin |
Views: | 12 |