
|
|
Fault tolerance in distributed systems is the capability to continue operating smoothly despite failures or errors in one or more of its components. This resilience is crucial for maintaining system reliability, availability, and consistency. By implementing strategies like redundancy, replication, and error detection, distributed systems can handle various types of failures, ensuring uninterrupted service and data integrity. Fault Tolerance in Distributed System In distributed systems, three types of problems occur. All these three types of problems are related.
Important Topics for Fault Tolerance in Distributed System What is Fault Tolerance?Fault Tolerance is defined as the ability of the system to function properly even in the presence of any failure. Distributed systems consist of multiple components due to which there is a high risk of faults occurring. Due to the presence of faults, the overall performance may degrade. Types of Faults
Need for Fault Tolerance in Distributed SystemsFault Tolerance is required in order to provide below four features.
Fault Tolerance in Distributed SystemsIn order to implement the techniques for fault tolerance in distributed systems, the design, configuration and relevant applications need to be considered. Below are the phases carried out for fault tolerance in any distributed systems. 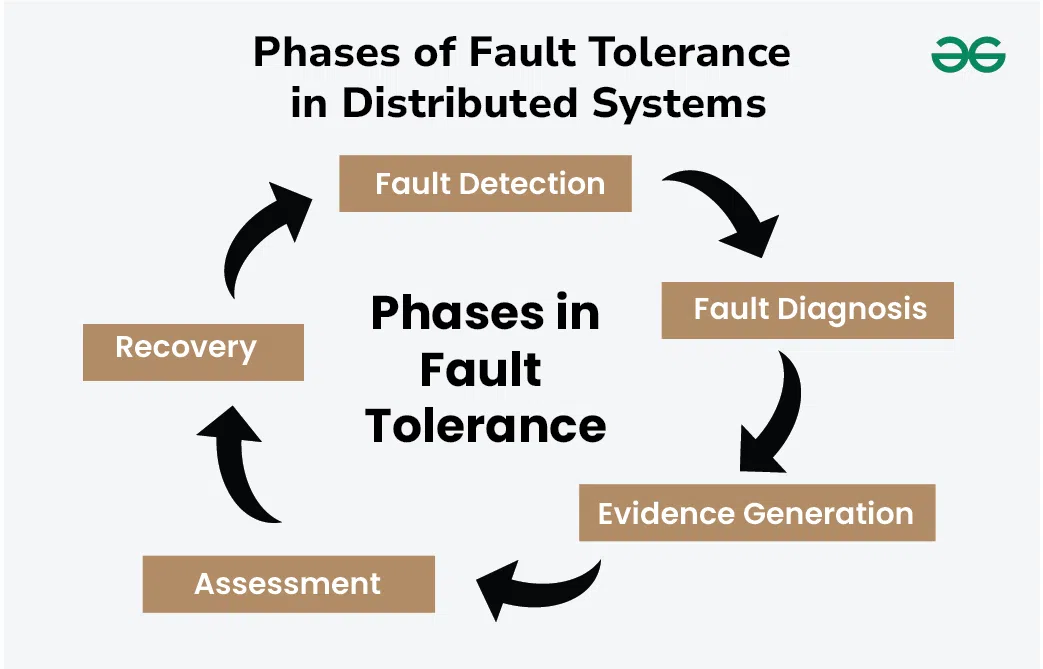 Phases of Fault Tolerance in Distributed Systems 1. Fault DetectionFault Detection is the first phase where the system is monitored continuously. The outcomes are being compared with the expected output. During monitoring if any faults are identified they are being notified. These faults can occur due to various reasons such as hardware failure, network failure, and software issues. The main aim of the first phase is to detect these faults as soon as they occur so that the work being assigned will not be delayed. 2. Fault DiagnosisFault diagnosis is the process where the fault that is identified in the first phase will be diagnosed properly in order to get the root cause and possible nature of the faults. Fault diagnosis can be done manually by the administrator or by using automated Techniques in order to solve the fault and perform the given task. 3. Evidence GenerationEvidence generation is defined as the process where the report of the fault is prepared based on the diagnosis done in an earlier phase. This report involves the details of the causes of the fault, the nature of faults, the solutions that can be used for fixing, and other alternatives and preventions that need to be considered. 4. AssessmentAssessment is the process where the damages caused by the faults are analyzed. It can be determined with the help of messages that are being passed from the component that has encountered the fault. Based on the assessment further decisions are made. 5. RecoveryRecovery is the process where the aim is to make the system fault free. It is the step to make the system fault free and restore it to state forward recovery and backup recovery. Some of the common recovery techniques such as reconfiguration and resynchronization can be used. Types of Fault Tolerance in Distributed Systems
Fault Tolerance StrategiesFault tolerance strategies are essential for ensuring that distributed systems continue to operate smoothly even when components fail. Here are the key strategies commonly used:
Design Patterns for Fault ToleranceDesign patterns for fault tolerance help in creating systems that can handle failures gracefully and maintain reliable operations. Here are some key fault tolerance design patterns: 1. Circuit Breaker PatternThis pattern prevents a system from making calls to a failing service by wrapping it in a “circuit breaker.” When the service fails, the circuit breaker trips, causing further calls to fail fast instead of trying to connect to a failing service repeatedly.
2. Bulkhead PatternThis pattern isolates different components or services to prevent a failure in one part of the system from affecting others. It’s similar to the bulkheads in a ship that prevent flooding in one compartment from sinking the entire vessel.
3. Retry PatternThis pattern involves automatically retrying an operation that has failed due to transient errors. The retries are typically done with exponential backoff to avoid overwhelming the system.
4. Rate Limiting PatternThis pattern controls the number of requests a system or service can handle within a specific time window to prevent overload and ensure fair usage.
5. Failover PatternThis pattern involves switching to a backup system or component when the primary one fails. It ensures continuity of service by having redundant systems ready to take over.
ConclusionFault Tolerance in Distributed Systems is a major task that needs to be accomplished. Faults can lead to a reduction in the overall performance of the system. The faults that arise also differ from one another. Therefore these faults need to be identified and handled according to the working, architecture, and applications of the given distributed systems. FAQs for Fault Tolerance in Distributed System1. What is the basic principle of Fault Tolerance?
2. What is meant by fault tolerance testing?
3. What is the difference between Fault Tolerance and Load balancing?
4. What is meant by fault in Distributed Systems?
|
Reffered: https://www.geeksforgeeks.org
| Distributed System |
Type: | Geek |
Category: | Coding |
Sub Category: | Tutorial |
Uploaded by: | Admin |
Views: | 16 |