|
|
Sigmoid function is one of the most commonly used activation functions in Machine learning and Deep learning. The sigmoid function can be used in the hidden layers, which take the output from the previous layer and brings the input values between 0 and 1. Now while working with neural networks it is necessary to calculate the derivate of the activation function. Sigmoid function is also known as the squashing function, as it takes the input from the previously hidden layer and squeezes it between 0 and 1. So a value fed to the sigmoid function will always return a value between 0 and 1, no matter how big or small the value is fed. Table of Content What is the Sigmoid Function?Sigmoid function is a mathematical function that has an “S”-shaped curve (sigmoid curve). It is widely used in various fields, including machine learning, statistics, and artificial intelligence, particularly for its smooth and bounded nature. The sigmoid function is often used to introduce non-linearity in models, especially in neural networks. Mathematical Definition of Sigmoid FunctionThe formula of the sigmoid activation function is:
Here, e is the base of the natural logarithm (approximately equal to 2.71828), and x is the input to the function. The graph of the sigmoid function looks like an S curve, where the function of the sigmoid function is continuous and differential at any point in its area. Properties of the Sigmoid FunctionSome of the common properties of sigmoid function
Derivative of the Sigmoid FunctionFor sigmoid function, [Tex]\sigma(x)= \frac{1}{1+e^{-x}}[/Tex] it’s derivative is given as:
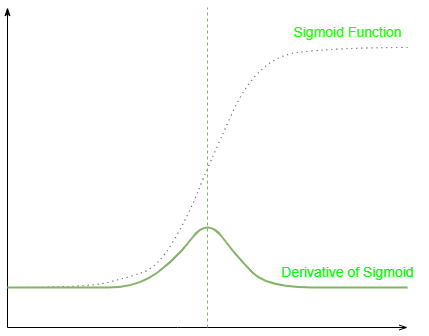
Let’s derive this derivative of sigmoid function as follows: Let [Tex]y = \sigma(x)= \frac{1}{1+e^{-x}}[/Tex] Let u = 1 + e-x. Thus, y = 1/u. First, find the derivative of u with respect to x : du/dx = -e-x. Then, find the derivative of y with respect to u: [Tex]\frac{dy}{du} = -\frac{1}{u^2}[/Tex] Apply the chain rule: [Tex]\frac{dy}{dx} = \frac{dy}{du} \cdot \frac{du}{dx} = -\frac{1}{u^2} \cdot (-e^{-x}) = \frac{e^{-x}}{(1 + e^{-x})^2}[/Tex] [Tex]\sigma(x) = \frac{1}{1 + e^{-x}}, 1 – \sigma(x) = \frac{e^{-x}}{1 + e^{-x}}[/Tex] Thus,[Tex] \sigma'(x) = \frac{e^{-x}}{(1 + e^{-x})^2} = \left( \frac{1}{1 + e^{-x}} \right) \left( \frac{e^{-x}}{1 + e^{-x}} \right) = \sigma(x) \left( 1 – \sigma(x) \right)[/Tex] Applications of Sigmoid FunctionIf we are using a linear activation function in the neural network then the model will only be able to separate the data linearly. Resulting a bad behavior on the nonlinear data. But if we add one more hidden layer with the sigmoid activation function then the model will also be able to perform better on a non-linear dataset and hence the performance of the model increases with non-linear data. Now while performing the backpropagation algorithm on the neural network, the model calculated and updates the weights and biases of the neural network, this updation will happen by calculating the derivative of the activation function. Since the derivative of the sigmoid function is very easy as it is the only function that appears in its derivative itself. Also, the sigmoid function is differentiable on any point, hence it helps calculate better perform the backpropagation algorithm in the neural network. Step 1: Differentiating both sides with respect to x. [Tex]\begin{aligned} F^{‘}(x) &= \frac{d}{dx}\left(\frac{1}{1+e^{-x} }\right )\\ \end{aligned}[/Tex] Step 2: Apply the reciprocating/chain rule. [Tex]\begin{aligned} F^{‘}(x) &= \frac{d}{dx}\left(\frac{1}{1+e^{-x} }\right )\\ &= -\frac{1}{\left(1+e^{-x} \right )^2}\frac{d}{dx}\left(1+e^{-x} \right )\\ &= -\frac{1}{\left(1+e^{-x} \right )^2}\cdot e^{-x}\frac{d}{dx}\left(-x \right )\\ &= \frac{e^{-x}}{\left(1+e^{-x} \right )^2} \end{aligned}[/Tex] Step 3: Modify the equation for a more generalized form. [Tex]\begin{aligned} \sigma^{‘}(x) &= \frac{e^{-x}}{\left(1+e^{-x} \right )^2}\\ &= \frac{1+e^{-x}-1}{\left(1+e^{-x} \right )^2}\\ &= \frac{1}{1+e^{-x} }-\frac{1}{\left(1+e^{-x} \right )^2}\\ &= \frac{1}{\left(1+e^{-x} \right )}\cdot \left(1 -\frac{1}{1+e^{-x}}\right )\\ &= \sigma(x) \left(1 -\sigma(x)\right ) \end{aligned}[/Tex] The above equation is known as the generalized form of the derivation of the sigmoid function. The below image shows the derivative of the sigmoid function graphically. Graph of the sigmoid function and its derivative Read More,
FAQs on Sigmoid FunctionWhat is the Sigmoid Function?
Why is the Sigmoid Function Used in Neural Networks?
Why Sigmoid Activation function is squeezing function?
What is the main issue with the sigmoid function while backpropagation?The main issue related to the activation function is when the new weights and biases are calculated by the gradient descent algorithm, if these values are very small, then the updates of the weights and biases will also be very low and hence, which results in vanishing gradient problem, where the model will not learn anything. Graphically, the sigmoid function looks as shown below which is similar to S but rotated 90 degrees anti-clockwise. 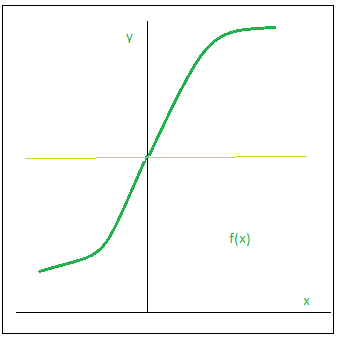 |
Reffered: https://www.geeksforgeeks.org
| AI ML DS |

Type: | Geek |
Category: | Coding |
Sub Category: | Tutorial |
Uploaded by: | Admin |
Views: | 11 |