|
|
Beautiful Soup is a Python library used for parsing HTML and XML documents. It provides a simple way to navigate, search, and modify the parse tree, making it valuable for web scraping tasks. In this article, we will explore how to import BeautifulSoup in Python. What is BeautifulSoup?BeautifulSoup is a Python library used for parsing HTML and XML documents. It creates a parse tree that allows you to navigate and manipulate elements within these documents effortlessly. This library is commonly used for web scraping tasks, where data needs to be extracted from web pages. BeautifulSoup handles malformed HTML well and provides a convenient interface to extract data by searching for tags, attributes, and more complex patterns within the document structure. Import BeautifulSoup in PythonBelow, we will explain step-by-step how to import BeautifulSoup in Python. Create a Virtual EnvironmentOpen VSCode and navigate to the directory where you want to work. Create a virtual environment using the terminal in VSCode. Install BeautifulSoup LibraryWith the virtual environment activated, install BeautifulSoup using pip: pip install beautifulsoup4BeautifulSoup Installation using Pip Import BeautifulSoup in Python ScriptOnce installed, you can import BeautifulSoup into your Python script or interactive session. Verify BeautifulSoup ImportNew we will write a simple Python script to verify if the BeautifulSoup module is successfully imported in Python or not. Let us see a few different examples of using the module. Extracting Text from HTMLIn this example, we use requests to fetch the HTML content of a webpage about Python from GeeksforGeeks. Using BeautifulSoup, we parse this HTML and demonstrate accessing and printing the title tag of the webpage, its tag name (title), and the name of its parent tag (head). Output: 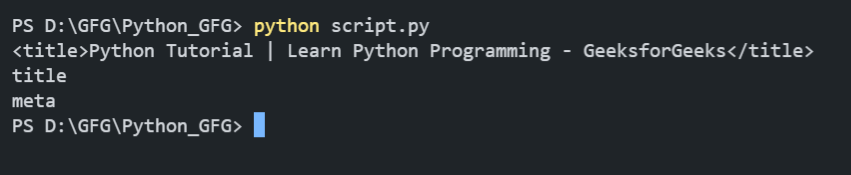 Extracting text from HTML using BeautifulSoup Parsing HTML StringIn this example, we are parsing a simple HTML string (html_doc) using BeautifulSoup. It extracts the title, the text of the first paragraph (<p>), and all items in a list (<ul>). Output:  Parsing HTML String using BeautifulSoup ConclusionIn conclusion, importing BeautifulSoup in Python is easier process that begins with creating a virtual environment and installing the library using pip. Once imported, BeautifulSoup allows efficient parsing, navigation, and extraction of data from HTML and XML documents, making it essential for web scraping tasks and beyond. |
Reffered: https://www.geeksforgeeks.org
| Python |
Type: | Geek |
Category: | Coding |
Sub Category: | Tutorial |
Uploaded by: | Admin |
Views: | 17 |